
はじめに
BERT(というよりHuggingfaceのTransformers)に関する勉強をしたくて買った本のコードをWindows(Linux)のローカル環境で動かしたくなったのでそこでの気づきを本記事に投稿。一般的にはWindowよりLinuxのほうが動作が安定したり、記事の数も多いので今回試みた。ちなみに環境は以下の通り。
OS :Windows11(Ubuntu 20.04.6 LTS)
GPU :NVIDIA GeForce GTX 1660 Ti
Python:3.10.12
<書籍名>BERT-GPT-3-DALL-自然言語処理・画像処理・音声処理-人工知能プログラミング実践入門

★関連リンク
業務で活用できるAI技集のまとめはこちら
最短で解説
ざっくり流れは以下のとおり。
①Ubuntu(Linux)で仮想環境つくる
②必要なライブラリをいれる
③コードを実行する
①Ubuntu(Linux)で仮想環境つくる
まずUbuntu上で仮想環境をつくる。Ubuntuを起動し、下記のコマンドで現在のディレクトリに新たな仮想環境用のフォルダができる(1行目)。そしてそれを有効化する(2行目)。
python -m venv myvenv
source myvenv/bin/activateちなみに仮想環境を消したかったら以下を実施。Optionで-rはディレクトリ削除、-fは警告非表示。
rm -rf myvenv②必要なライブラリをいれる
必要なライブラリは以下のとおり。下記を参考にpipコマンドでインストール。
#コーディング環境用。起動時のコマンドは「jupyter lab」 pip install jupyterlab #後でつかうrun_clm.pyを入手するためにgit cloneでtransformersをDLする #2行目はDLしたtransformersフォルダからtransformersをインストールするコマンド git clone https://github.com/huggingface/transformers pip install -e transformers #4.39.0.dev0で動作確認 #書籍ドキュメントどおりのコマンドで動作確認。動作しなかったらコメントのVersionを指定 pip install fugashi[unidic-lite] #1.3.0で動作確認 pip install ipadic #1.0.0で動作確認 #書籍とVersionを同じにしたらErrorが発生したので少し調整 pip install datasets=2.18.0 pip install sentencepiece==0.1.91 #FineTuningの実行時にライブラリ不足のErrorが発生したので予め入れておく。 pip install evaluate #0.4.1で動作確認 pip install accelerate #0.27.2で動作確認 pip install scikit-learn #1.4.1.post1で動作確認 #学習結果確認に必要 pip install tensorboard #2.16.2で動作確認
③コードを実行する
注意ポイントをいくつか記載。
・(4行目)run_clm.pyのパスが合っているか
・(7,8行目)学習/検証用データであるtrain.txtが存在するか
・(16行目)学習結果確認するなら記載(output_dir同様、フォルダは自動作成)
※学習データ:下記URLのdataset_plain.txtをtrain.txtとファイル名を変えて利用
akane-talk/docs at main · npaka3/akane-talk · GitHub
なおepochs=100とした場合、私の環境では完了までに6h 53min 14sかかった。
%%time
# ファインチューニングの実行
!python ./transformers/examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path=rinna/japanese-gpt2-medium \
--do_train \
--do_eval \
--train_file=train.txt \
--validation_file=dev.txt \
--num_train_epochs=100 \
--save_steps=5000 \
--save_total_limit=3 \
--per_device_train_batch_size=1 \
--per_device_eval_batch_size=1 \
--output_dir=output_gen/ \
--use_fast_tokenizer=False \
--logging_dir=runs/ \
--logging_steps=1ちなみに学習結果を確認する際はjupyterlab上でマジックコマンド(%で始まるコマンド)打ってもtensorboardがうまく出てこなかったので、Ubuntu上で下記コマンドを実行して指定のURL(http://localhost:xxxx)にアクセスしたらうまくいった。
tensorboard --logdir runs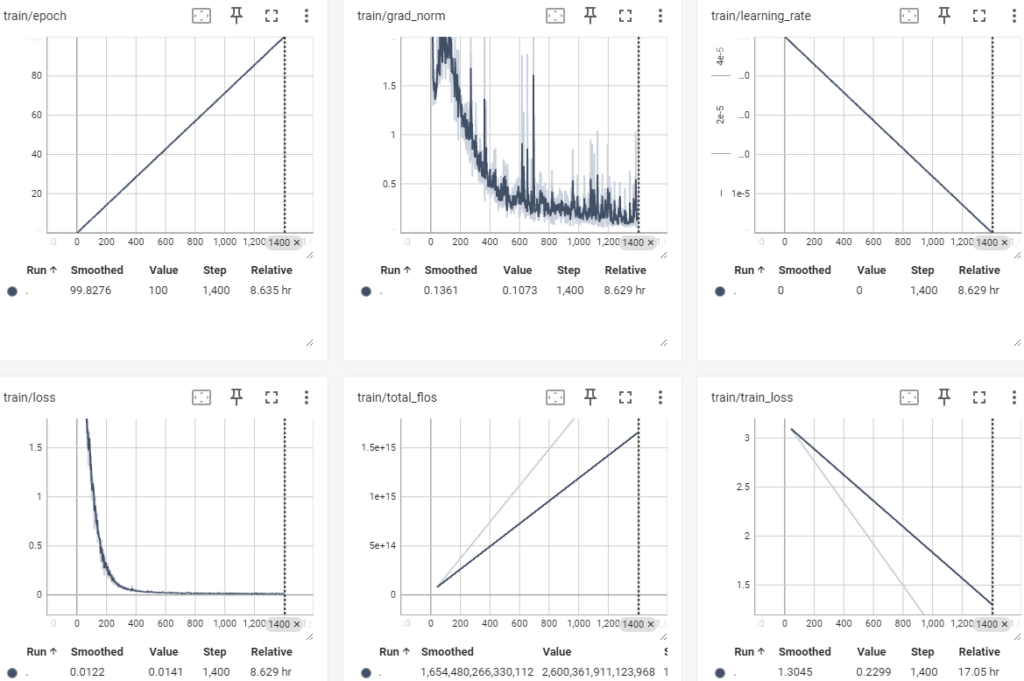
ファインチューニング後のモデル利用は下記コードで実施可能。ファインチューニング前にしたかったら、「output/」の部分を「rinna/japanese-gpt2-medium」に置換すればOK。
import torch
from transformers import T5Tokenizer, AutoModelForCausalLM
# テキストの準備
text = 'こんにちは、'
# トークナイザーとモデルの準備
tokenizer = T5Tokenizer.from_pretrained('rinna/japanese-gpt2-medium')
model = AutoModelForCausalLM.from_pretrained('output_gen/')
# テキストをテンソルに変換
input = tokenizer.encode(text, return_tensors='pt')
# 推論
model.eval()
with torch.no_grad():
output = model.generate(input, do_sample=True, max_length=100, num_return_sequences=1)
print(tokenizer.batch_decode(output))

コメント