
はじめに
「JDLA Generative AI Test 2024」のシラバスに記載のあった単語を中心に解説。
【JDLA公式】Generative AI Test – 一般社団法人日本ディープラーニング協会【公式】
テスト概要
テスト名:
JDLA Generative AI Test
試験形式:IBT形式(インターネット経由で自宅や指定の会場から受験可能)
出題形式: 選択問題と記述問題
問題数: 20問程度
試験時間: 20分
受験料:2,200円(税込)
受験資格:制限なし (年齢、国籍、経験など不問)
試験内容:生成AIの基礎知識、活用方法、リスクへの対策など
その他:合格者にはオープンバッジが付与(試験結果の確認期間は、受験日から6ヶ月間)
模擬問題
これといった試験対策が見当たらなかったので、練習問題(正誤判定問題)を1,000問ほど作ってみました。ランダムで出題されますので、腕試しに解いてみて下さい。
筆者の試験結果
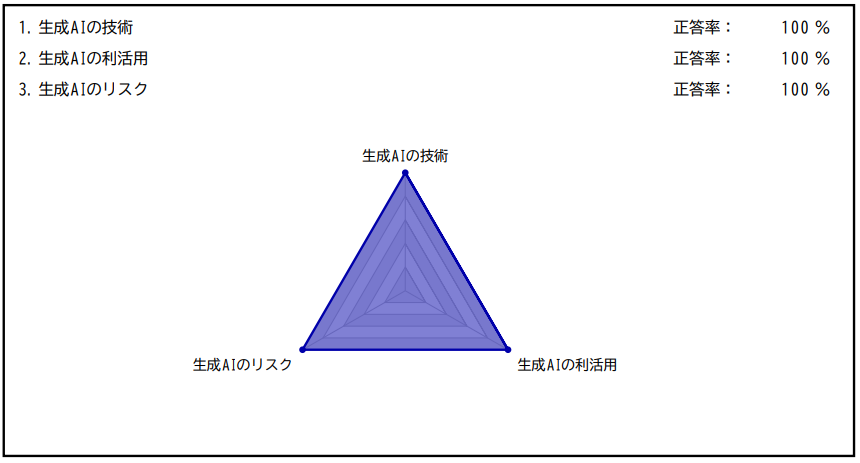
JDLA Generative AI Test 2024 #1を受検した結果、満点で合格。
試験詳細
以下はテスト受検時の実体験をもとに記載。問題カテゴリは主に以下のように分類される。カンニング防止のため、問題文のコピーや解答欄へのテキスト貼り付けは仕様上不可能となっている。
| カテゴリ | 内容 |
| 選択問題(単数) | 所感で20問中8~10問程度。回答を1つ選べばよいので難易度は低め。単数選択問題がたくさん出てきた人はラッキー? |
| 選択問題(複数) | 所感で20問中8~10問程度。「不適切・適切なものをすべて選べ」のどちらも出てくるので問題文はしっかり読むこと。 |
| 記述問題 | 最後の1問。「問題内容を理解する→文章を考える→解答欄にタイピング」のプロセスは結構時間を要するため最低2~3分は残しておきたい。コピペは不可。 |
点数を稼ぐためのコツ
過去問は少ししか公式HPに公開されていないため、基本的には生成AIのニュースに常に関心を持ったり、シラバスで分からない単語があれば自分なりに理解を深める(後述)ことが常套手段となる。しかし今回の試験対象は”数学や物理”など唯一解が存在するジャンルではなく、”生成AI”という漠然とした概念であるため、悪魔の証明が絡む問題、一般論を問う問題は知識がなくても得点しやすい傾向にある。これは今回の試験に限らず、あらゆる分野の資格試験に有効な手段のため、以降は概念的に例を挙げて説明する。とにかく重要なのは出題者の立場で考えることである。
悪魔の証明が絡む問題
最初は悪魔の証明が絡む問題から。例えば、次の中で「適切なものを選べ」という問題に、
・○○というものが存在する
という選択肢があった場合、基本的には○になりやすい。
なぜなら「存在する」ことを証明するには最低1例を示すだけで良いが、「存在しない」ことを証明するには世界中のありとあらゆるものを確認する必要があり、事実上証明は不可能だからである。したがって出題者の立場からすると、この選択肢(○○というものが存在する)を×にすることは難しく、必然的に○となる可能性が高くなる。
同じような理由で、
・△△できる可能性がある
という選択肢も文脈にはよるものの、○になる可能性は高い(∵明らかな場合を除き、可能性がないと断言できる根拠提示が困難なため)。
あとは言い切り系の選択肢も、よほどの一般論が浸透していない限りは、100%断言できる根拠提示が困難なため正答を導きやすい。
・必ず□□、確実に□□、常に□□、□□は不要である
一般論を問う問題
つづいて一般論を問う問題について。これも例を見た方がはやい。例えば、次の中で「適切なものを選べ」という問題に、
・××は重要である
・☆☆した方がよい
・▽▽が必要である
という選択肢があった場合、一般論として明らかな場合を除いて○をつけたほうが正答率があがる。なぜなら人や業種・業界によって様々な価値観があり、多様性が受容される現代社会において、万人が共通する回答を一意に決めることは難しいためである(例えば”重要”という言葉は人によって価値観が違うため明確な場合以外は否定しにくい)。こちらも出題者の意図を汲むと自ずと答えが見えてくる。
★関連リンク
業務で活用できるAI技集のまとめはこちら
シラバス単語集
シラバスに記載している単語の一部を解説。学習の方向性として言葉の意味を一言一句覚えるというよりかは、概念として理解を深める形を推奨する。自分の言葉でその単語を説明できるようになればベスト。
生成AIの技術(39words)
確率モデル
与えられたデータや事象に対して確率分布を用いて確率を推定するモデルのこと(下図参照)。大規模言語モデルは膨大な量のWebテキストを学習しており、人間らしい言葉のチョイスを選択することができている。ちなみにChatGPTで同じ質問をしても、全く同じ解答が返ってこないのは確率モデルを用いているため。
ハルシネーション
生成AIがもっともらしい偽情報を生成すること。生成AI(大規模言語モデル)は確率モデルを用いているため、学習データに誤りがあったり、学習量が少なかったりする場合に誤った答えを導く可能性が高まる。
[参考] ディープフェイク
生成AI等の深層学習(ディープラーニング)を利用して作成された偽画像や偽動画のこと。ハルシネーションは異なり、意図的に作られたでありサイバー攻撃の一種とされている。ウクライナ軍トップの偽動画(ゼレンスキーは我が国の敵だ。と呼びかけている)等が話題となった。
基盤モデル
大量のデータで学習(事前学習)させたモデルのこと。膨大な計算リソースを使わないと作成できないことから個人ではなかなか難しい。
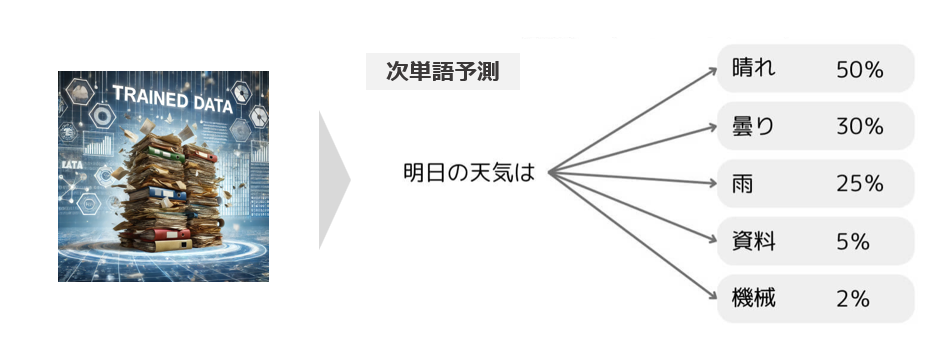
言語モデル
人間の言葉を単語の出現確率でモデル化したもの。例えば、「今日は公園で」という文に対して、次に続く単語を「遊ぶ:70%, 集まる:25%, ...」と確率を表して表現する。
大規模言語モデル (LLM)
大量のテキストデータを使って訓練された自然言語処理モデルのこと。パラメータ数が多いのが特徴で、OpenAIのGPT-4や、MetaのLhamaなどが有名。
Transformer
自然言語処理のためののアーキテクチャ。文章の中の単語同士の関係を理解し、意味を考慮して文を生成したり、翻訳したりできる。有名なChat-GPTの"T"は、実はこのTransformerの略。
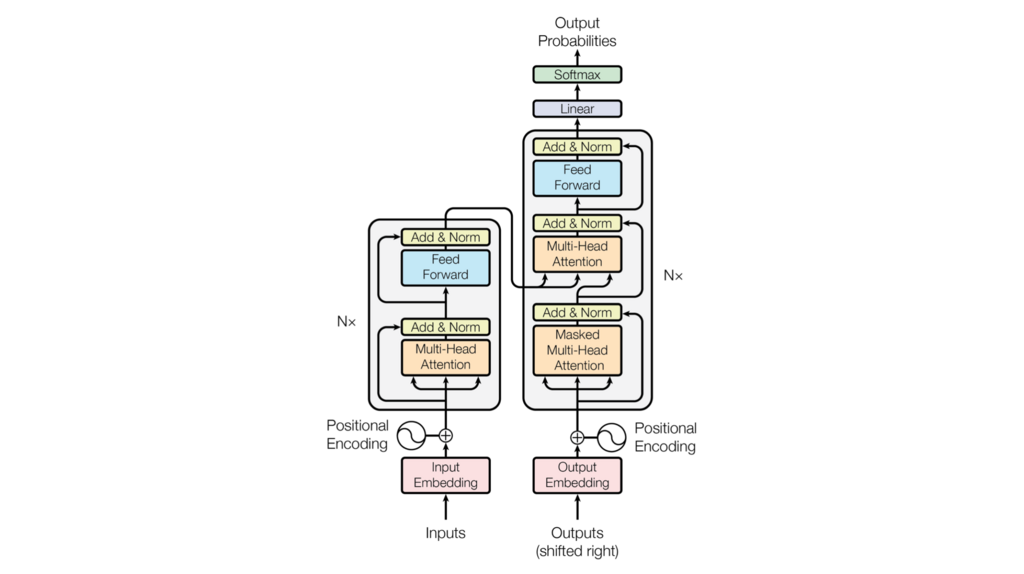
[参考]Transformerの構造
構造はエンコーダ(左半分)とデコーダ(右半分)からなる。詳細は割愛するが、GPTはデコーダ部分を活用して作られたモデルで文章生成が得意。BERTはエンコーダ部分を活用して作られたモデルで分類タスクが得意。Pythonを用いたBERTの分類タスクについてはこちらで詳しく解説。ちなみに論文はこちら。
Attention
入力の各要素の重要度を計算し、重要な情報に注目するメカニズム。自然言語分野の飛躍はこの技術のおかげといっても過言ではない程すごいもの。Transformerにも多数使われている。
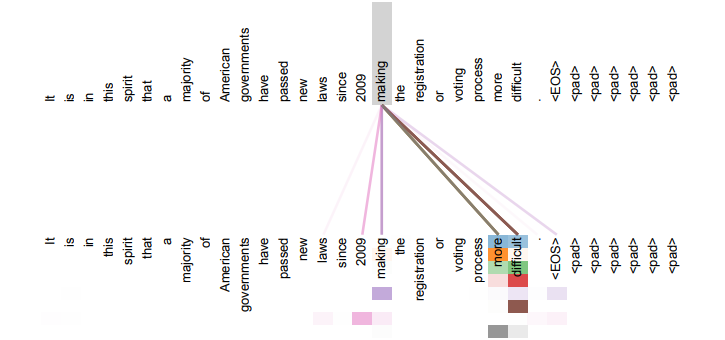
[参考]Attentionの視覚的解釈
Attentionは単語と単語の関係性を数値で表現することができる。詳しくは「Attention Is All You Need」という論文を参照。
GPT-3
OpenAIが開発した最先端の大規模言語生成モデル。パラメータ数は1750億個で、自然な文章を生成し多様なタスクに適用可能。
[参考] GPT-3の特徴
構造はTransformerのデコーダ部分を活用されて作られており、その膨大なパラメータ量・学習量から高精度の回答を出力することが可能。またFew-Shot(入力テキストに命令したい内容の具体例など参考情報となる情報を記載すること)を実施することで更なる精度向上が可能。またZero-Shot(入力テキストに命令したい内容をいきなり記載すること)でも人間に近しい性能を発揮できる能力をもつことで有名。
教師あり学習
教師あり学習は、入力データとそれに対応する正解ラベル(教師データ)のペアを使用してモデルを訓練する機械学習手法。正解データを作るのが面倒なのが課題。
自己教師あり学習
データ作成の稼働を減らすために自動で教師データを作って学習させる手法。具体的にはネット上にある膨大な文章で穴埋め問題を作ったり、次の単語を予測したりすることで精度を高める。
事前学習
AIモデルを特定のタスクに適用する前に行う学習過程のこと。特定のタスクに特化せず、大量の一般的なデータセットを使用して、言語理解や画像認識などの基本的な能力を身につけさせる。
ファインチューニング
AIモデルが事前学習を経て基本的な知識や能力を獲得した後、特定のタスクやデータセットに対して最適化するプロセスのこと。
アラインメント (Alignment)
人間の価値や目標に従って、人工知能システムが行動し意思決定すること。ロボットが人間を傷つけたり、危害を加えてはならないようにするための議論や研究のこと。
[参考] OpenAIのアラインメントチームが解散
GPT-4oを発表後にサツキバー氏の辞任しアラインメントチームが解散した。これはアルトマン氏の開発優先の姿勢が、サツキバー氏の安全重視の考えと衝突した結果ともいわれている。
人間のフィードバックによる学習
別名RLHF(Reinforcement Learning from Human Feedback)で強化学習の一種。人間の価値基準に近づけるために文字通り、人からの直接フィードバックで訓練を行う。
インストラクション・チューニング (Instruction Tuning)
ユーザの指示に沿った出力を生成することを目的とした教師あり学習のこと。これにより学習済みLLMがユーザからの指示に対してより適切に反応するようになる。
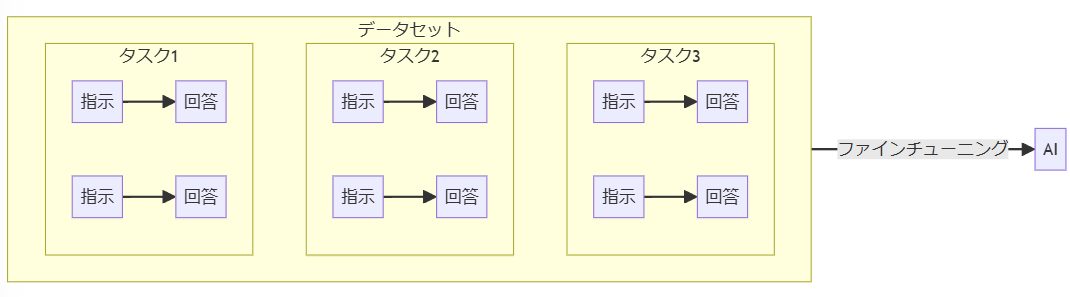
[参考]イメージ図
指示と回答をセットにして様々なタスクを学習することで未知のタスクにも対応。
コンテキスト内学習 (In-Context Learning)
モデルが新しいタスクを追加の訓練なしに理解し、適応する能力を指す。例えば、GPTモデルは広範なWebデータ(CommonCrawl)を学習することで、この能力を保有していると考えられている。これにより、モデルはZero-Shot(事前に訓練されていないタスクでも対応可能)やFew-Shot(少量の事例で新しいタスクをこなす)を実現可能。
[参考]具体例
例えば以下のように「英語をフランス語に変えて欲しい」というタスクがいきなり実行できるのも、入力文を理解・適応できる能力を学習できているため。

Zero-Shot
モデルが直接学習していないタスクやカテゴリーに対しても予測を行う能力のこと。ChatGPTに対して無茶ぶりしても、ある程度しっかり答えてくれるのはこの能力のおかげ。
[参考] 事例
ChatGPTでいうと以下のようなイメージ。(いきなりタスクを実行させる)

Few-Shot
モデルに対して、少しの具体例を与えることで未知のリスクやカテゴリーに対しても予測を行う能力のこと。Zero-Shotに比べて精度が高くなるのが特徴。
[参考] 事例
ChatGPTでいうと以下のようなイメージ。(助走となる文を記載して実行させる)

Chain-of-Thought
問題を解くまでの一連の手順をプロンプトに含める技術のこと。例えばChatGPTで文章問題の計算をさせたいとき、入力文に類似問題の計算過程を説明することによって正答率を高めることができる。
サンプリング手法
生成モデルが出力するデータの分布から特定のサンプルを選ぶ方法のこと。例えばChatGPTで多様性を上げたければ、Temparture(ランダム性・予測確定度)を上げるなどの調整が可能。
リーダーボード
モデルの性能を評価・比較するためのランキングシステムのこと。これにより性能比較や技術の透明性、コミュニティの形成などが可能になった。
[参考] kaggleのリーダーボード(Titanic - Machine Learning from Disaster)
kaggleとは世界中の機械学習を学ぶ人のための海外のPlatformのこと。誰でも機械学習のコンペ参加や学習コンテンツの利用をすることが可能。
ベンチマーク
生成AIがどれくらい優れているかを定量的評価するための指標。
[参考] 指標の種類
・マッチングベース
例えばBLEU等は正解の文章に対してどれくらい一致しているかを計測する。再現性も高く計算コストも低いことからお手軽にできる利点がある一方、語順が考慮されていなかったり字面だけで判断しているので正確性が必ずしも高いとは限らない。
・人間ベース
RLHF(Reinforcement Learning from Human Feedback)のように、人間が出力結果を判断し定量的な評価に変換する手法。人が判断するので再現性や計算コストは高いが、人間の価値基準に近しいものを評価することができる。
・生成ベース
GPT-4など強力なモデルで評価を行う手法。当然ながら正確性は評価するモデルに依存し、モデルの精度が高ければ高いほど正確性が高くなる。
条件付き生成、拡散モデル (Diffusion Model)
少しずつノイズを加えて、その壊れた状態から逆変換することでデータ生成を実現するモデル。主に画像系の生成AIで使われる。
[参考] Stable Diffusion
イギリスのStability AIが開発した画像生成AIサービス。テキストを入力するだけで画像を出力することができる。当ページでGoogle Colabを使った生成AIの使い方を解説。

オープンコミュニティ
モデルやデータが公開されており、知識の発信は共有ができる場のこと。当サイトで解説しているコンテンツで利用するHugging FaceやGithubもその一種。
[参考] Hugging Face
ニューヨークに拠点を置くユニコーン企業が作ったAI開発用のプラットフォーム。Transformersなどの強力なライブラリやモデルも多数保有しており、当サイトでもいくつかのページで解説している。例:ELYZA-japanese-Llama-2-13bを使った日本語文章作成など

オープン大規模言語モデル
MetaのLhamaやxAIのGrokなど、一般のサイトで公開されているモデルのこと。GPT-4などはOpenAIがモデル本体は非公開としているので対象外。
[参考] 有名なLLMとオープン化有無について
GPT-4(OpenAI):非公開。ただしGPT-2まではHugging Faceで公開。
Lhama(Meta):HuggingFaceで公開。2024.4に最新のLhama3をリリース。
Gemini(Google):非公開。旧Google Bard。ただし別に公開されたGemmaはオープンモデル。
Grok(xAI):Githubで公開。イーロンマスク率いるX(旧Twitter)をベースに学習したことで有名。
Claude(Anthropic):非公開。Anthropic社は元OpenAI所属のメンバーで立ち上げられた企業。
オープンデータセット
AIや機械学習のモデル訓練に使われる大規模データのうち、一般公開されているものを指す。画像系、音声系、文章系など様々なジャンルが存在する。
[参考] 画像系データセット:MNIST
AI(特に画像系)を勉強する際に必ずお世話になるデータセット。読み方は「えむにすと」。手書き数字70,000万枚の画像+正解ラベルを無料でダウンロードでき、画像認識タスクの訓練用に活用。

オープンソース プログラムを構成するソースコードを広く一般に公開し、誰でも自由に扱ってよいとする考え方。無料で利用でき、自由に修正やカスタマイズが可能。
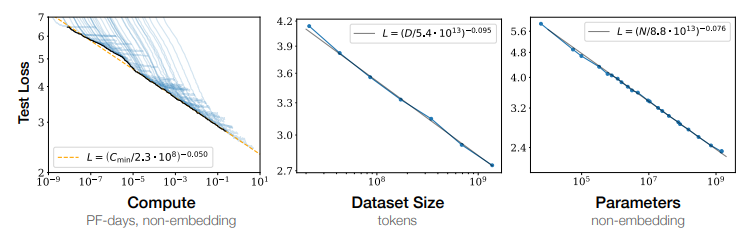
スケーリング則 (Scaling Laws)
モデルのサイズ(パラメータ数)、学習するデータセットのサイズ、学習につかう計算量(epoch数)の3つが同時に上昇すれば性能も上昇していくという法則。
[参考]Scaling Lawsに関する論文
海外文献(すべて英語)だが、詳細を確認することが可能。データセットを増やさずパラメータだけ増やしても上手くいかないなど、分かりやすく解説されている。
データセットのサイズ
スケーリング則の要素の一つ。一般的にサイズが大きいとモデルの汎化能力の向上、過学習の防止、データ偏りの緩和等を実現することができる。
データセットの質
モデルの性能に影響を及ぼす重要な要素のひとつ。“Garbage In, Garbage Out(ゴミを入れたらゴミしかでない)”という有名な言葉の通り、データの質私大でモデル性能も低くなってしまう。
モデルのパラメーター数
スケーリング則の要素の一つ。一般的に数が大きいとモデル性能が上昇するが、動かすための計算リソースも大きくなる。
[参考] 有名なLLMのパラメータ数
GPT-4(OpenAI):非公開(推定で100兆)
GPT-3.5(OpenAI):非公開(推定で3,550億)
Lhama3(Meta):700億
Gemini-Ultra(Google):1.6兆
Grok-1(xAI):3,140億
Claude2(Anthropic):非公開
計算資源の効率化
スケーリング則のひとつである"計算量"の大規模化を実現するために必要な考え方。具体的な手法として、モデル/データの並列化・量子化などがある。当サイトでも解説あり。
[参考] PEFT(Parameter-Efficient Fine Tuning)
LLMをFine Tuningする際に、全体を再学習せずにモデルの一部を更新するだけで性能向上させる手法のこと。後述のLoRAもPEFTの一種。また量子化を加えたQLoRAという手法も存在する。※一般的に量子化をするとパラメータのの計算精度が落ちる反面、メモリの量を低減することができる。
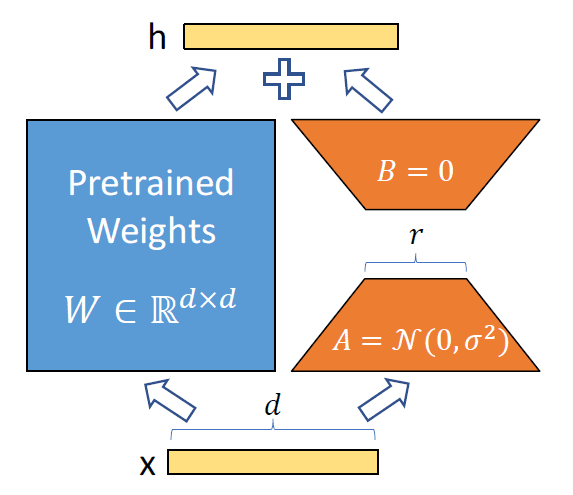
LoRA
Low-Rank Adaptationの略。通常、Fine Tuningの際はモデルの全パラメータの情報を保持しつつ更新を行うため膨大なメモリが必要となるが、この手法では行列を駆使して差分計算のみを行う。
[参考]どれだけパラメータを削減できるか
例えば事前学習のパラメータがd×dだった場合、元のパラメータは固定し、更新分のパラメータΔWを低ランク行列A(d×r),B(r×d)を用いてΔW=ABと定義するとパラメータ数を2drで表現することが可能。結果、rがdに対してとても少ない数(例えば2とか)にすることで、大幅にパラメータ数を削減することができるという仕組み。※図は論文から引用
GPU
Graphics Processing Unitの略。もともとはコンピュータの画像処理に使われていたが、最近はその並列での演算処理能力の高さからAIに活用されるようになってきた。
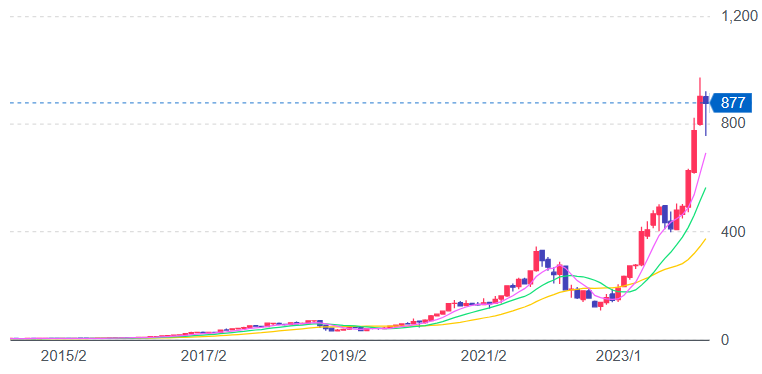
[参考] NVIDIA
GPUといえばGeForceシリーズを有するNVIDIAが有名。近年、生成AIが活発になり計算資源のニーズが高まったことから、2023年頃から株価は急騰。2024年2月にはアルファベット(Google)を超えて世界の時価総額ランキングで4位となった。(下図はYahoo!ファイナンスでのNVIDIA株価)
マルチモーダル
テキスト・画像・音声・動画など複数の種類のデータを同時処理できるAI技術のこと。AIが人間のように複雑な情報を理解し、より自然な方法で対話するのに役立つ。(例:自動運転など)
学習データの時間的カットオフ
AIモデルの訓練に使用するデータセットが特定の時点までの情報のみを含むように制限すること。これにより、過去の古いデータを削除して偏りを無くしたりすることができる。
大規模言語モデルの知識
※説明範囲が特定できないため割愛
大規模言語モデルの不得意タスク
一般的に学習を行っていない領域が対象となる。たとえばGPT-4は2023年4月までの情報しか保有しておらず、最新情報に疎い可能性がある。その他、専門的な内容、計算問題などが挙げられる。
生成AIの利活用 (15words)
ケイパビリティ
Capabilityとは"能力"のことで、生成AIにおいては、テキスト生成・画像生成・音声合成・翻訳・スタイル変換(img2txt等)を指す。
活用事例
ブログなどのコンテンツ作成、広告コピーの作成、個別学習サポート、エンターテイメントへの利用など様々なジャンルで利活用されている。
プロンプトエンジニアリング
生成AIモデルに対して効果的なプロンプト(入力文)を設計し、望ましい出力を得るための技術や手法のこと。
ハッカソン
「ハック(hack)」と「マラソン(marathon)」を組み合わせた造語。「ハック(hack)」は、創造的なプログラミングや技術的な問題解決を指し、「マラソン(marathon)」は、限られた時間内で集中的に取り組むことを意味する。
自主的なユースケース開発
個人や組織が自らのニーズや目標に基づいて、生成AI技術を応用した独自のアプリケーションやソリューションを創出すること。これには、特定の業務の自動化、新しい製品やサービスの開発、既存プロセスの改善などが含まれる。
インターネット・書籍、活用の探索
AIモデルが情報を生成する際に、インターネット上のデータや書籍などの豊富な情報源を参照し、学習することで、より正確で有用なコンテンツを提供する方法を模索すること。
生成AIの学習データ
AIモデルが訓練されるために使用されるテキスト、画像、音声などの大規模なデータセットのこと。
生成AIの性能評価
モデルの出力品質を測定し、その有用性や正確性を判断するために行われる。有名なものにBLEUスコア、ROUGEスコア、Perplexityなどがある。
生成AIの言語能力
自然言語を理解し、生成する能力のことを指す。文法と構文の理解、文脈理解、多言語対応、意味の把握創造性、創造性、適応性などが挙げられる。
LLMを利用したサービス (ChatGPT, Bard, Claude など)
ChatGPT(OpenAI)、Gemini(Google)、Claude(Anthropic)、LLaMA(Meta)が有名。
RAG (Retrieval-Augmented Generation)の利用
生成AIモデルの一種で、情報検索(リトリーバル)とテキスト生成(ジェネレーション)を組み合わせたアプローチのこと。これを活用すれば学習していない社内文書をAIに組み込むことができる。
エージェント・コード生成
ユーザーの自然言語による指示や質問に基づいて、AIが適切なプログラムコードを生成すること。エージェントとは特定の目的やタスクを自律的に実行するために設計されたソフトウェアまたはシステムのことで、代表例はチャットボット。
外部ツール呼出し
AIモデルがタスクを実行する際に、他のソフトウェアやサービスを利用して補助的な機能を提供するプロセスを指す。API利用はRAGなどもその一種と考えられる。
広告クリエイティブへの応用
AI技術を利用して広告のコンテンツを自動生成し、クリエイティブなプロセスを効率化することを指す。広告文を作成したり、動画広告を作成することも可能。
ドメイン固有
特定の分野や業界(ドメイン)に特化して設計・訓練されたAIモデルやシステムを指す。一般的な生成AIモデルが広範なトピックに対応できるのに対し、ドメイン固有の生成AIは特定の専門知識やデータに基づいてより高精度で専門的なアウトプットを提供することを目的としている。


コメント