
はじめに
Style-Bert-VITS2とは、簡単に言うと数秒のサンプル音声データだけで、好きな日本語のセリフを喋らせることができるモデルのこと。以下サイトのコードをGoogle Colab環境で実施した際の注意点を記載colab.ipynb – Colaboratory (google.com)。
とりあえず音声生成だけしたい方は、こちらのデモサイトを参考に。
※テキスト→音声のみ。モデル作成(=自分の準備した声を喋らせる)はできない。
★関連リンク
業務で活用できるAI技集のまとめはこちら
動画・音声ファイルからテキストを抽出したい場合はこちら
画像ファイルからテキストを抽出したい場合はこちら
解説
Style-Bert-VITS2 v2.6.0
2024.6.23時点で最新のVerを解説。Google Colab上で動作が確認できたものの、注意点がいくつかあったため、少しだけ解説を加える。
①必要なライブラリ等のインストール [5分]
まずはgoogleドライブのマウントを行う。本家のコード(v2.6.0)と順番は異なるが、こちらの方があとの動作で都合がよくなる。
from google.colab import drive
drive.mount("/content/drive")
%cd /content/drive/MyDriveその後、gitコマンドで”/content/drive/MyDrive”の配下に”Style-Bert-VITS2″のフォルダを作成する。ここでOOM(メモリ容量超過)のメッセージが出た場合は、しばらく放置しておいても問題ない。
※画面が真っ白になっても更新ボタンを押すと復帰可能
import os
os.environ["PATH"] += ":/root/.cargo/bin"
!curl -LsSf https://astral.sh/uv/install.sh | sh
!git clone https://github.com/litagin02/Style-Bert-VITS2.git
%cd Style-Bert-VITS2/
!uv pip install --system -r requirements-colab.txt
!python initialize.py --skip_default_models[参考] メモリ超過の対策
今回のコマンドで特に動作が重いのは下の2行。したがって、この2行は上の行と切り離して独立させて3回に分けて実行するとメモリ超過になりにくい。
1回目 : import os~%cd Style-Bert-VITS2/まで
2回目 : !uv pip install --system -r requirements-colab.txt
3回目 : !python initialize.py --skip_default_models
[参考] ファイル操作のコマンド
Google ColabはUNIX上で動作しているので以下のコマンドでファイル関連の情報を得ることができる。よく使うコマンドを記載したので参考にして頂きたい。
%pwd : 現在のパスを表示する
%ls : 現在のパスに存在するファイル/フォルダを表示する
%cd [移動後のパス]:現在のパスを変更する
②各種設定 [5分]
実行する前に「Style-Bert-VITS2」フォルダ内にある「input」フォルダにサンプルの音声ファイル(wav形式)を格納する。手持ちの動画データ(mp4)からwav変換したければ以下のサイトで何もインストールする必要なくWeb上で変換が可能。MP4からWAVへのコンバータ- FreeConvert.com
# 学習に必要なファイルや途中経過が保存されるディレクトリ
dataset_root = "/content/drive/MyDrive/Style-Bert-VITS2/Data"
# 学習結果(音声合成に必要なファイルたち)が保存されるディレクトリ
assets_root = "/content/drive/MyDrive/Style-Bert-VITS2/model_assets"
import yaml
with open("configs/paths.yml", "w", encoding="utf-8") as f:
yaml.dump({"dataset_root": dataset_root, "assets_root": assets_root}, f)# 元となる音声ファイル(wav形式)を入れるディレクトリ
input_dir = "/content/drive/MyDrive/Style-Bert-VITS2/inputs"
# モデル名(話者名)を入力
model_name = "your_model_name"
# こういうふうに書き起こして欲しいという例文(句読点の入れ方・笑い方や固有名詞等)
initial_prompt = "こんにちは。元気、ですかー?ふふっ、私は……ちゃんと元気だよ!"
!python slice.py -i {input_dir} --model_name {model_name}
!python transcribe.py --model_name {model_name} --initial_prompt {initial_prompt} --use_hf_whisper# JP-Extra (日本語特化版)を使うかどうか。日本語の能力が向上する代わりに英語と中国語は使えなくなります。
use_jp_extra = True
# 学習のバッチサイズ。VRAMのはみ出具合に応じて調整してください。
batch_size = 4
# 学習のエポック数(データセットを合計何周するか)。
# 100で多すぎるほどかもしれませんが、もっと多くやると質が上がるのかもしれません。
epochs = 100
# 保存頻度。何ステップごとにモデルを保存するか。分からなければデフォルトのままで。
save_every_steps = 1000
# 音声ファイルの音量を正規化するかどうか
normalize = False
# 音声ファイルの開始・終了にある無音区間を削除するかどうか
trim = False
# 読みのエラーが出た場合にどうするか。
# "raise"ならテキスト前処理が終わったら中断、"skip"なら読めない行は学習に使わない、"use"なら無理やり使う
yomi_error = "skip"from gradio_tabs.train import preprocess_all
from style_bert_vits2.nlp.japanese import pyopenjtalk_worker
pyopenjtalk_worker.initialize_worker()
preprocess_all(
model_name=model_name,
batch_size=batch_size,
epochs=epochs,
save_every_steps=save_every_steps,
num_processes=2,
normalize=normalize,
trim=trim,
freeze_EN_bert=False,
freeze_JP_bert=False,
freeze_ZH_bert=False,
freeze_style=False,
freeze_decoder=False,
use_jp_extra=use_jp_extra,
val_per_lang=0,
log_interval=200,
yomi_error=yomi_error,
)[参考] 音声ファイルのError
wavファイルが3~5秒くらいの音声データだとうまく処理できずエラーがでることがあった。その場合は10秒くらいまでのデータを準備することで問題なく対応することができた。
[参考] Google Colab上でのファイル格納の方法
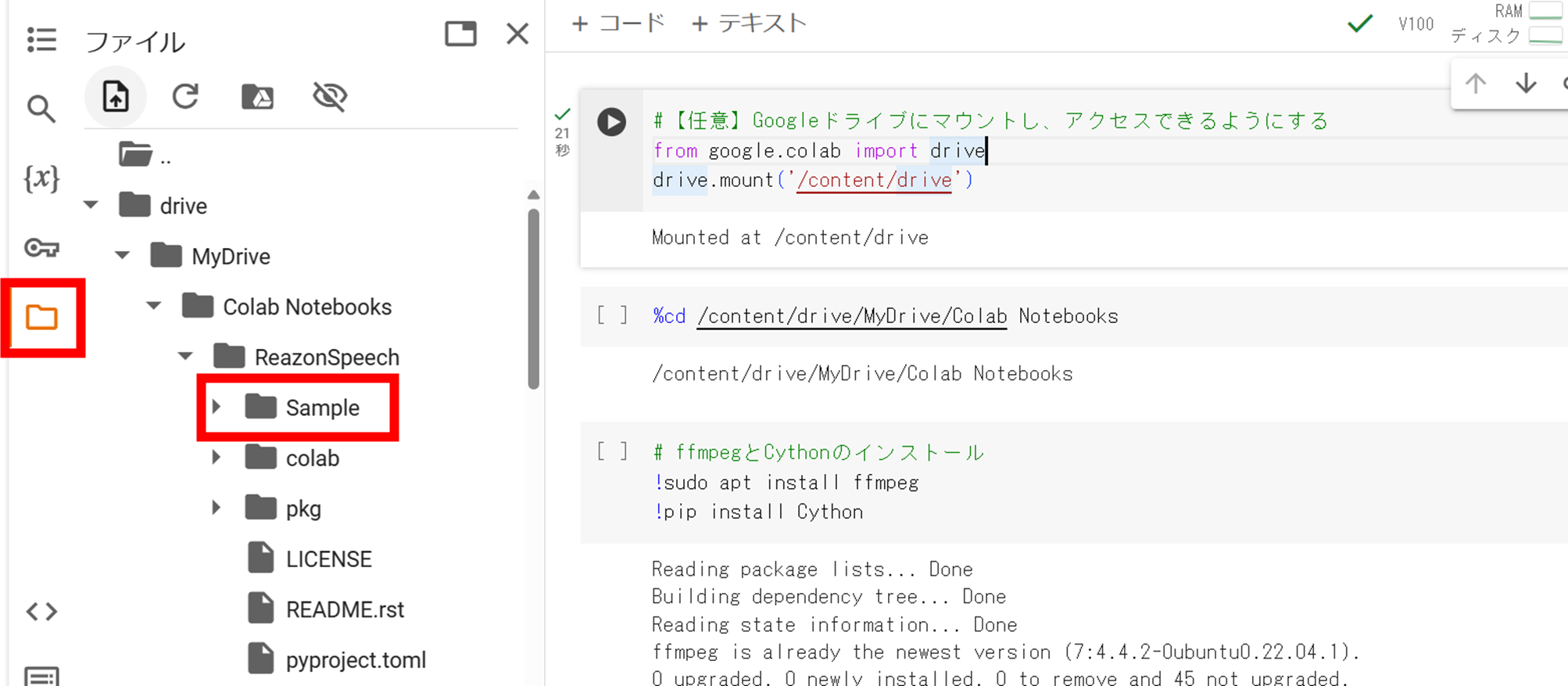
Googleドライブにマウントした状態(下図の右上コマンドを実行した状態)で左側にあるファイルアイコンをクリックすると、フォルダの階層がツリー表示される。主な操作は以下の通り。
・任意のフォルダ作成: 余白の部分で[右クリック]→[新しいフォルダ]
・ファイルのアップロード:ツリー表示上の格納先フォルダへファイルをドラッグ&ドロップ
※下図の赤枠(Sampleフォルダ)にファイルを重ねる
上記以外にもGoogleドライブのいうサイトからブラウザ上でファイル操作することも可能。
[参考] フリーソフトで変換する方法
Web上で変換せずにローカル環境で実施したい場合は、HD Video Converter Factoryというソフトを利用するやり方もある。詳細はこちらのページのAppendixを参照。
③学習・実行 [5分]
入力したwavファイルをもとに学習開始。
import yaml
from gradio_tabs.train import get_path
paths = get_path(model_name)
dataset_path = str(paths.dataset_path)
config_path = str(paths.config_path)
with open("default_config.yml", "r", encoding="utf-8") as f:
yml_data = yaml.safe_load(f)
yml_data["model_name"] = model_name
with open("config.yml", "w", encoding="utf-8") as f:
yaml.dump(yml_data, f, allow_unicode=True)学習が終わったらアプリを起動する。以下のようなUIが起動できれば成功。
# 学習結果を試す・マージ・スタイル分けはこちらから
!python app.py --share
Style-Bert-VITS2 v2.4.1
2024.6.23時点ではなぜか学習の前処理(preprocess_all)がいつまでも終わらなく、Google Colab上でうまく動作ができなかった。メモ用として残しておくが、動作させたい場合はv2.6.0のほうを読んで頂きたい。
①必要なライブラリ等のインストール [5分]
実行ファイルと同階層に「Style-Bert-VITS2」という名前のフォルダが自動作成される。その後、cdコマンドでフォルダ内にアクセスし、必要なライブラリをインストールする。
!git clone https://github.com/litagin02/Style-Bert-VITS2.git
%cd Style-Bert-VITS2/
!pip install -r requirements.txt
!python initialize.py --skip_jvnv[参考] セッション再起動の警告について
原因は不明だが以下のポップが出てきても、セッションを再起動を押して最初から実行し直せば2度目は問題なく実行可能。

②各種設定 [5分]
実行する前に「Style-Bert-VITS2」フォルダ内にある「input」フォルダにサンプルの音声ファイル(wav形式)を格納する。手持ちの動画データ(mp4)からwav変換したければ以下のサイトで何もインストールする必要なくWeb上で変換が可能。MP4からWAVへのコンバータ- FreeConvert.com
# 学習に必要なファイルや途中経過が保存されるディレクトリ
dataset_root = "Data"
# 学習結果(音声合成に必要なファイルたち)が保存されるディレクトリ
assets_root = "model_assets"
import yaml
with open("configs/paths.yml", "w", encoding="utf-8") as f:
yaml.dump({"dataset_root": dataset_root, "assets_root": assets_root}, f)
# 元となる音声ファイル(wav形式)を入れるディレクトリ
input_dir = "inputs"
# モデル名(話者名)を入力
model_name = "my_test_model"
# こういうふうに書き起こして欲しいという例文(句読点の入れ方・笑い方や固有名詞等)
initial_prompt = "こんにちは。元気、ですかー?ふふっ、私は……ちゃんと元気だよ!"
!python slice.py -i {input_dir} --model_name {model_name}
!python transcribe.py --model_name {model_name} --initial_prompt {initial_prompt} --use_hf_whisper# JP-Extra (日本語特化版)を使うかどうか。日本語の能力が向上する代わりに英語と中国語は使えなくなります。
use_jp_extra = True
# 学習のバッチサイズ。VRAMのはみ出具合に応じて調整してください。
batch_size = 4
# 学習のエポック数(データセットを合計何周するか)。
# 100で多すぎるほどかもしれませんが、もっと多くやると質が上がるのかもしれません。
epochs = 100
# 保存頻度。何ステップごとにモデルを保存するか。分からなければデフォルトのままで。
save_every_steps = 1000
# 音声ファイルの音量を正規化するかどうか
normalize = False
# 音声ファイルの開始・終了にある無音区間を削除するかどうか
trim = False
# 読みのエラーが出た場合にどうするか。
# "raise"ならテキスト前処理が終わったら中断、"skip"なら読めない行は学習に使わない、"use"なら無理やり使う
yomi_error = "skip"
from gradio_tabs.train import preprocess_all
preprocess_all(
model_name=model_name,
batch_size=batch_size,
epochs=epochs,
save_every_steps=save_every_steps,
num_processes=2,
normalize=normalize,
trim=trim,
freeze_EN_bert=False,
freeze_JP_bert=False,
freeze_ZH_bert=False,
freeze_style=False,
freeze_decoder=False, # ここをTrueにするともしかしたら違う結果になるかもしれません。
use_jp_extra=use_jp_extra,
val_per_lang=0,
log_interval=200,
yomi_error=yomi_error
)③学習・実行 [5分]
入力したwavファイルをもとに学習開始。
import yaml
from gradio_tabs.train import get_path
dataset_path, _, _, _, config_path = get_path(model_name)
with open("default_config.yml", "r", encoding="utf-8") as f:
yml_data = yaml.safe_load(f)
yml_data["model_name"] = model_name
with open("config.yml", "w", encoding="utf-8") as f:
yaml.dump(yml_data, f, allow_unicode=True)
!python train_ms_jp_extra.py --config {config_path} --model {dataset_path} --assets_root {assets_root}学習が終わったらアプリを起動する。以下のようなUIが起動できれば成功。
!python app.py --share
[参考] モデルの追加について
他の音声ファイルで新たなモデルを作りたい場合、以下の対応を行うことで実現可能。
1. inputフォルダの音声ファイル(.wav)を入れ替える
2. ②各種設定のモデル名(model_name)を変更する
3. ②各種設定のコード以降をすべて実行する
[参考] アプリの再起動について
アプリを再起動したい場合、すべてのコードを最初から実行すると時間が掛かってしまう。特にモデルを追加しない場合は、以下の手順を推奨。
Google Colab利用:①必要なライブラリ等のインストール→③学習・実行の後半(!python app.py --share)
ローカル環境 :③学習・実行の後半(!python app.py --share)
Appendix
音声合成の質を高めるためにできることを記載。
①テキストをいろいろ変化してみる
発音が変だなとおもったら、伸ばし棒「ー」を入れてみたり、漢字をひらがなにしてみたり、試行錯誤をしてみる。あとは改行を駆使してみたり、アクセント調整(0 or 1)で微調整も可能。あと音声生成はランダム性があるので、同じ設定で繰り返し実行を行い、欲しい音声が出てくるのを待つのもひとつの手法である(波形をよく見ると毎回違うものが生成されていることが分かる)。
②すこしゆっくり喋らせたい
詳細設定のLengthを大きくすると、音程を変えずにゆっくり喋らせることが可能。ちなみにSDI Radioを入れると発音間隔の緩急が大きくなる。
③音声は明瞭かつ少し長めに
公式では2~12(14)秒と書いてあるが、実際は短い(5秒程度)音声だとうまくいかなかった。経験則としては10~30秒程度のwavファイルを1ファイルだけ用意するだけ(書き起こしなし)でもうまく動作することができた。また音声が小さすぎるとうまくモデルを作れないことがあったため、長さが十分なのに失敗する場合は、サンプル音声が明瞭に聞こえるかを確認すると良い。


コメント