
はじめに
今回は文章から感情を読み取る「感情分析」について紹介。例えば、アンケート結果(フリーコメント)に記載のある内容がネガティブ or ポジティブなのかを言語モデルを使って判定していくイメージ。応用すればTwitterの投稿記事のネガ・ポジを自動判定することも可能。
今回は会社内で使うことを想定して、ローカル環境かつオフライン状況で実行できるソースを紹介。
※準備段階ではWebに接続する前提で記載(あくまで実行環境がオフライン)
★関連リンク
業務で活用できるAI技集のまとめはこちら
手順(オンラインで実行)
①必要ライブラリのインストール [1分]
まずは必要なライブラリをインストールする。必要なものは以下の通り。
pip install transformers
pip install torch
pip install fugashi
pip install ipadic[参考] 動作時のライブラリのバージョン
transformers 4.40.2
torch 2.3.0
fugashi 1.3.2
ipadic 1.0.0
[参考] fugashiとipadic
いずれもMecabという日本語の解析ツールを利用して「分かち書き」をするために必要なもの。分かち書きとは日本語の文章を分解する手法のこと。英語の文だと単語ごとにスペースで区切られているので分解する必要性が低いが、日本語の文は単語が連続するため、言語モデルに読み込ませるときにはこの工程が必要になる。ちなみにfugashiはPython上でMecabを簡単に使えるようにしたもの(Wrapper:ラッパーと言う)、ipadicはMecab用の辞書に相当する。
②実行 [3分]
textの部分は任意の文字列を入れて実行すると、出力結果として”POSITIVE”、つまり肯定的な文章であると判定された。scoreは確率を示しており今回の例は約98.8%の確度となった。なおこの出力結果の精度は利用する言語モデルに依存するため、必ずしも望んだ回答がくるとは限らない点に要注意。
from transformers import pipeline, AutoModelForSequenceClassification, BertJapaneseTokenizer
# パイプラインの準備
model = AutoModelForSequenceClassification.from_pretrained('koheiduck/bert-japanese-finetuned-sentiment')
tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
nlp = pipeline("sentiment-analysis",model=model,tokenizer=tokenizer)
text = "お前のことが大好きだ!"
result = nlp(text)
print(result)[{‘label’: ‘POSITIVE’, ‘score’: 0.9879671931266785}]
[参考] ざっくりコード解説
今回のプログラムは①言語モデルを定義、②トークナイザを定義、③pipelineで実行の3stepになる。トークナイザとは単語をベクトル(モデル利用するための入力形式)に変換するもの、pipelineとは定義したモデル&トークナイザを使って簡単に推論を実行できるコードのこと。
手順(オフラインで実行)
①必要ライブラリのインストール [1分]
まずは必要なライブラリをインストールする。必要なものは以下の通り。またオフライン環境では予め言語モデル等をローカル環境に保存する必要があるため、以下のサイトからデータをすべてダウンロードして指定フォルダ名の中に格納すること。※対象フォルダはプログラムのコードと同階層に格納する前提で以降は記載する
| 種類 | URL | フォルダ名 |
| 言語モデル | koheiduck/bert-japanese-finetuned-sentiment · Hugging Face | bert-japanese-finetuned-sentiment |
| トークナイザ | tohoku-nlp/bert-base-japanese-whole-word-masking at main (huggingface.co) | bert-base-japanese-whole-word-masking |
pip install transformers
pip install torch
pip install fugashi
pip install ipadic[参考] モデルのダウンロード方法
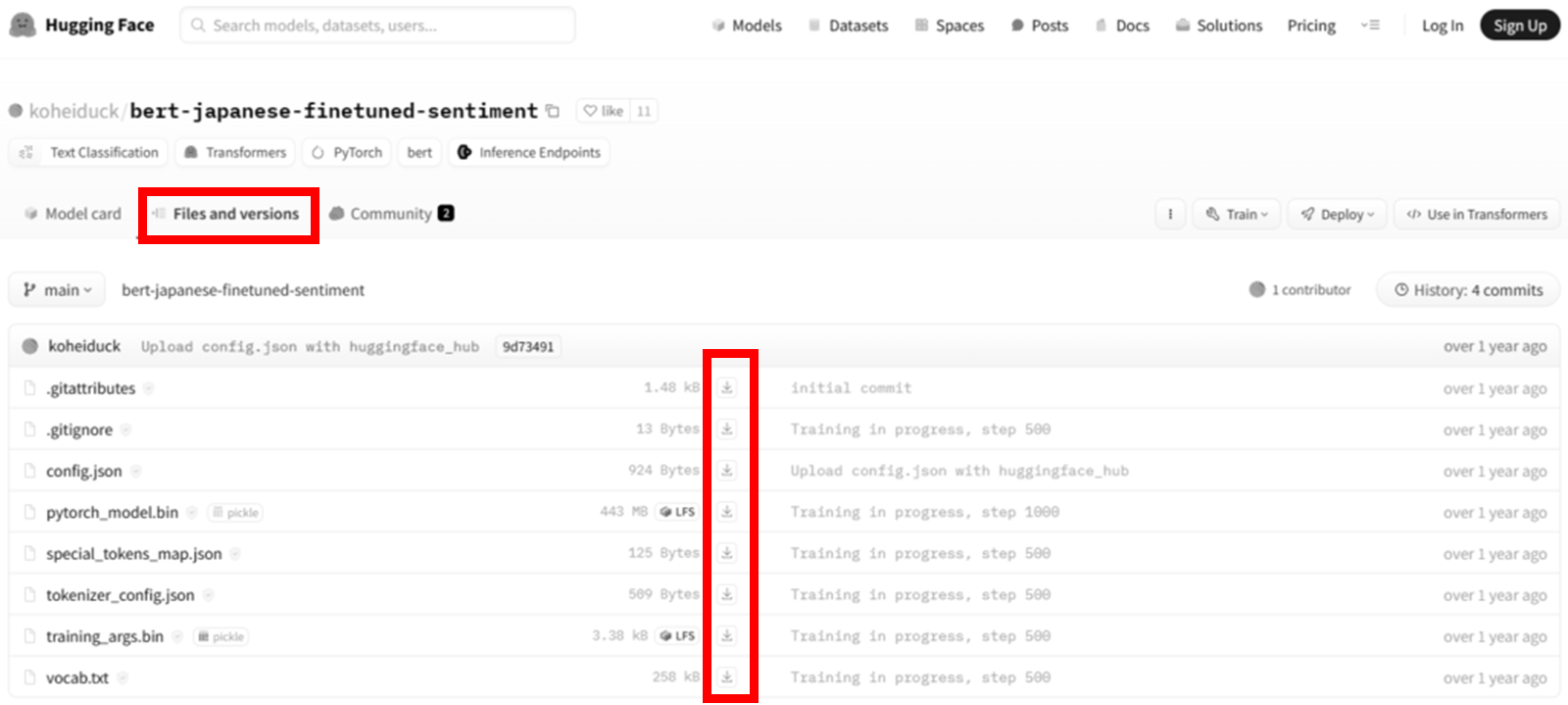
Hugging Faceのサイトにアクセスしたら「File and versions」を開き、すべてのファイルをダウンロードする。もし分からなければ、下記イメージを参考にして頂きたい。
②実行 [3分]
textに任意の文字を入れて実行。結果の3つの数値は順番に「NEUTRAL、NEGATIVE、POSITIVE」となる。今回の例では[0.0089, 0.0032, 0.9880]となり、POSITIVEの確率が98.8%と読み取れる。ちなみにこの結果はpipeline(オンライン)で実行した結果と一致する。なお、device=’cuda:0’はGPUありの場合の結果であり、cpu環境の場合はdevice=’cuda:0’となる。
import torch
import torch.nn.functional as F
from transformers import AutoModelForSequenceClassification, BertJapaneseTokenizer
# GPU有無の確認
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# パイプラインの準備
model = AutoModelForSequenceClassification.from_pretrained('koheiduck/bert-japanese-finetuned-sentiment')
tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
model.to(device)
text = "お前のことが大好きだ!"
token_ids = tokenizer.encode(text, add_special_tokens=True, return_tensors="pt")
output = model(token_ids.to(model.device))
probs = F.softmax(output.logits, dim=1)
print(probs[0])tensor([0.0089, 0.0032, 0.9880], device=’cuda:0′, grad_fn=<SelectBackward0>)


コメント
I am really impressed with your writing skills and also with the format for your weblog. Is that this a paid subject matter or did you customize it yourself? Either way keep up the excellent high quality writing, it is uncommon to look a nice weblog like this one these days!