
はじめに
Pythonで画像からテキストにする技術(OCR: Optical Character Recognition 光学的文字認識)について解説。画面キャプチャした画像データや、紙ベースのものをカメラで撮影したものを文章化するのにとても便利。今回はGoogle Colab上で動作させるパターンで実施。処理自体は軽いので、CPU環境でも実施可能。
★関連リンク
業務で活用できるAI技集のまとめはこちら
動画・音声ファイルからテキストを抽出したい場合はこちら
少量の音声ファイルから好きな音声を喋らせたい場合はこちら
手順
①必要ライブラリのインストール [1分]
tesseractというライブラリが光学式文字認識エンジン。pyocrはPython用のOCRラッパー。この2つを使って画像→テキスト変換を実現する。
!pip install pyocr
!apt install tesseract-ocr libtesseract-dev tesseract-ocr-jpn[参考] ラッパーとは
英語でWrapper。文字通りある複雑な処理を包み込んで、簡単なコーディングだけでOCRの処理をできるようにしたもの。プログラミングをしていると割とよく見かける用語。
②Googleドライブをマウント [1分]
下記コマンドを実行後、テキスト化したい画像ファイルを、Googleドライブ上に保存する。詳細は参考を参照。特に手元に画像ファイルがなければ、以下をDL。
from google.colab import drive
drive.mount('/content/drive')[参考] Google Colab上でのファイル格納の方法
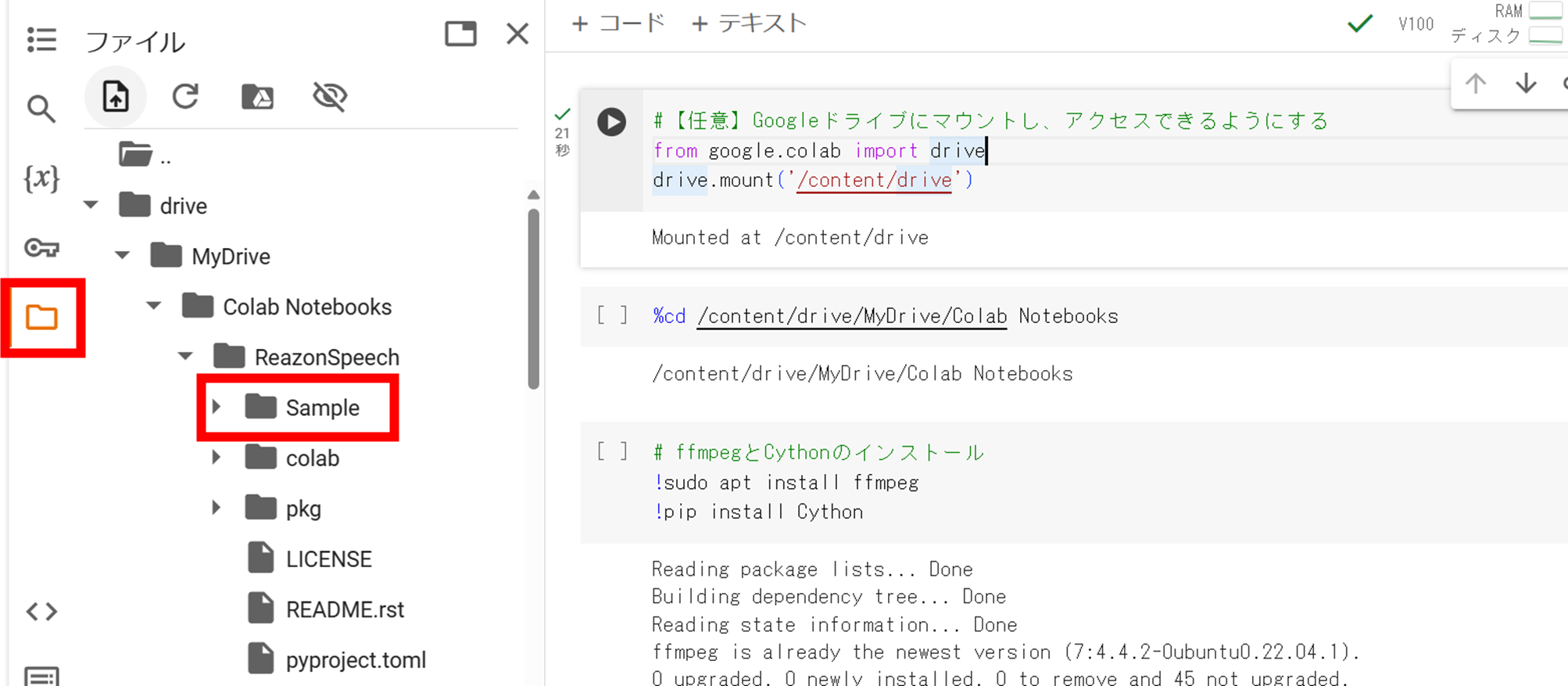
Googleドライブにマウントした状態(下図の右上コマンドを実行した状態)で左側にあるファイルアイコンをクリックすると、フォルダの階層がツリー表示される。主な操作は以下の通り。
・任意のフォルダ作成: 余白の部分で[右クリック]→[新しいフォルダ]
・ファイルのアップロード:ツリー表示上の格納先フォルダへファイルをドラッグ&ドロップ
※下図の赤枠(Sampleフォルダ)にファイルを重ねる
③実行 [1分]
実行して問題なければ、テキストが出力される。
from PIL import Image
import pyocr
tools = pyocr.get_available_tools()
tool = tools[0]
img = Image.open("test.png")
txt = tool.image_to_string(img, lang='jpn+eng', builder=pyocr.builders.TextBuilder(tesseract_layout=6))
print(txt)[参考] sample.pngでの実行結果
sample.png(上図)をテキスト変換した結果、下図のような結果が得られた。最初の行に「ファアイル」という誤字?が見当たるが、それ以外は正確に実行できていることが分かる。
↓

Appendix
・出力結果の修正について
上記の通り、出力されたテキストは必ずしも100%正確に出力されるとは限らない(むしろ必ずどこかに誤りがあることの方が多い)。そういった場合、人間の目でチェックするのも良いが、ChatGPTの力を借りてしまった方が効率的なケースがある。GPT-3.5(無料版)でも十分しっかり校閲してくれるので、ぜひお勧めしたい(下図)。ちなみにもしOpenAIのAPIがあれば、一連の動作をすべてPythonで記述することも可能。
次の文章で、文法的な誤り・誤字があれば、正しい形に修正して下さい。
-------
(出力された文章)
・クリップボードの画像をテキスト化する例
クリップボードの扱いはGoogle Colabでは実現できないので、Windowsのローカル環境でPythonを構築した場合のコードを以下に記載。今回はtesseractではなくeasyocrを採用。tesseractに比べてOCRの時間は掛かるが、easyocrはpipコマンドでライブラリがインストールできるので楽。
※tesseractはWindows環境だとexeファイルでインストールする必要があるのでちょっと面倒。一方、Google Colabは前述のとおりLinux環境なのでaptコマンドでインストール可能。
from PIL import ImageGrab
import easyocr
reader = easyocr.Reader(['ja','en'], gpu=False)
screenshot = ImageGrab.grabclipboard()
screenshot.save('tmp.png')
results = reader.readtext('tmp.png')
texts = ""
for (bbox, text, prob) in results:
texts += text
print(texts)

コメント