
はじめに
対象者:文章生成AIをうまく使って会社の資料を検索・要約できるようにしたい人
ゴール:自分のPCで会社の資料(pdf)の検索・要約ができるようになる
制約条件:有料、Python環境構築、オンライン
いま世間で流行っているChatGPTですが、なかなか業務でうまく使えないです。
具体的にどう使えないのかしら?
例えば業界用語や社内の専門用語を含んだ質問しても答えてくれなかったり…
なるほど。それならRAGという技術を使って、社内ドキュメントとChatGPTを上手く連携させるのはどうかしら。早速やってみましょう!(難易度:★★★☆☆)
★関連リンク
業務で活用できるAI技集のまとめはこちら
会議時に自動で議事録をとりたい方はこちら
資料用の簡単な図をChatGPTに書かせたい方はこちら
資料用の簡単な絵をChatGPTに書かせたい方はこちら
研修のワークやe-learningをAIにサポートしてもらいたい方はこちら
[参考] RAGって何?
RAG(検索拡張生成)とは、超ざっくりいうと生成AIにカンニングペーパーを持たせてあげること。もう少しちゃんと説明するならば、ChatGPTなどの大規模言語モデル(生成AI)に外部情報の検索を組み合わせることで精度を向上させる仕組みのこと。通常のChatGPTは、質問を生成AIに投げて回答をもらう形となるが、RAG利用時は質問者と生成AIとの間に社内資料を予めベクトルDB化したものを準備し、質問時に質問内容に近しいベクトルを抽出することで、生成AIが保持していない情報を検索することができる。
[通常時]
[RAG利用時]


手順 難易度:★★★☆☆
①OpenAIのAPI取得 難易度:★☆☆☆☆
まず初めに生成AIを利用するためにOpenAIのAPIを取得する。具体的な手順については以下のページを参考にして頂きたい。なおOpenAIのAPI KEYを取得したら必ず控えておくこと。
【No.L013】OpenAI APIの取得方法: 5分で完了する手順 – GIS Academy
ちなみにこのAPIは従量制で使った分だけお金を取られる仕組みになっているが、どうしても有料が厳しければ一般公開されているLLMを使うことも可能。但しある程度の回答精度を出すためにはパラメータ数が大きいモデルを使う必要があり、これを動作させるためには相応のPCスペックが必要となるため、まずはOpenAIの有料版をお勧めする。
[参考] 予算について
OpenAIのAPIは有料サービスにつき、いきなり社内で本格利用するにはハードルが高い。したがってまずはトライアルということで小規模の金額(~数万円)で決済を取ることをお勧めする。実際のところ数万円を課金しておけば、思った以上に利用単価が安いのでほとんど金銭面気にせず利用できるし、自動引き落としをOFFにすれば必要以上に徴収されるリスクも無くなる。トライアルで「数万課金するだけで●●だけ工数削減できた」ということを証明し、その後本格運用に持ち込む流れが望ましい。
②Python環境を整える 難易度:★★☆☆☆
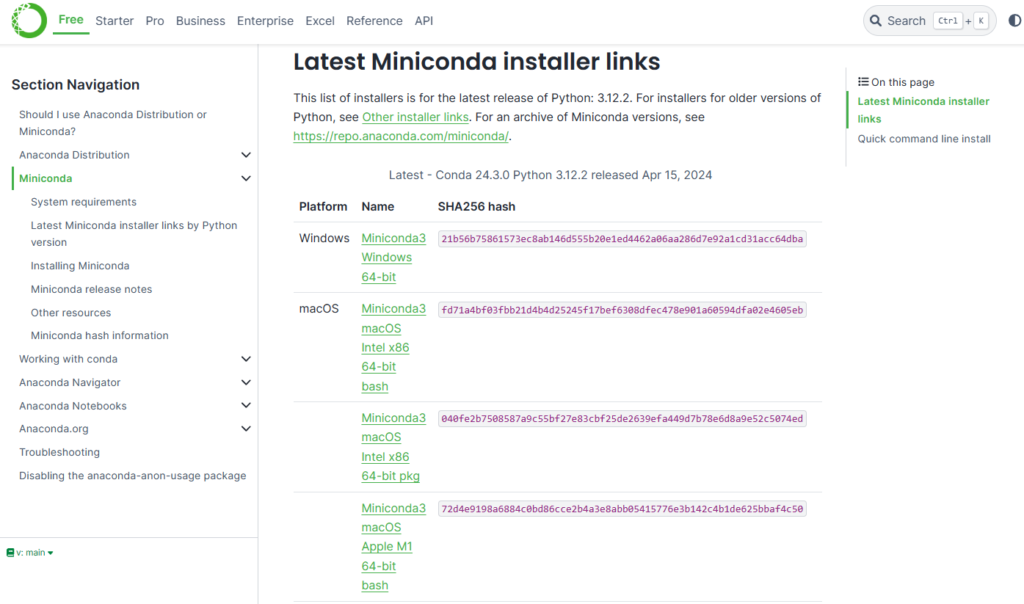
続いて実施するのが、ローカル環境にPythonと呼ばれるプログラム実行環境を整えること。法人利用であればMinicondaという開発環境をインストールするのがお勧め。よくWebサイトにはPython環境構築=Anacondaのような風潮があるが、こちらは現在「従業員200名以上の法人は有償」なので社内で利用する場合は規約違反になる恐れがある点に要注意。
Webサイトにアクセスすると下図のような画面が開くので、ご自身の環境(Windows or macOS or Linux)に合わせてダウンロードする。その後、ダウンロードしたファイルを開いてインストールをおこなう。インストール手順はひたすらクリックしていくだけなので割愛。
[参考] Pythonとは?
Pythonとはプログラミング言語の1つで、機械学習やAIに関する豊富なライブラリがあることで有名。"プログラミング"と聞くと抵抗がある方もたくさんいると思うが、当HPでは基本的にコピペで進められるよう解説を進めていくため、その点は安心していただきたい。
※Pythonの特徴
・可読性が高い:構文が明確で読みやすい。プログラム初心者に人気。
・豊富なライブラリ:機械学習/AIをはじめとするライブラリがたくさんあって実現性が高い
Minicondaのインストールが無事完了すると「Anaconda Powershell Prompt」というアプリケーションが追加されているのでこちらを起動する。起動すると黒い画面が立ち上がるので、まずはPythonが動作するかチェックするため、以下コマンドを投入して実行してみる。結果として以下のような画面(最終行に>>>)がでたら成功なので[Ctrl+z]→[Enter] でPythonの対話モードから抜ける。
python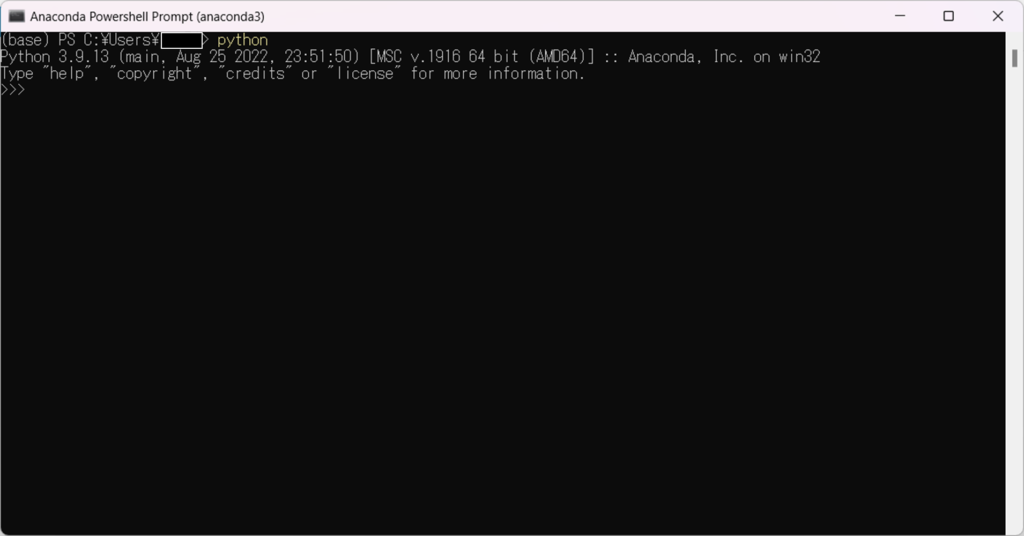
次は実際にプログラムを記載&実行できる環境を構築する。以下のコマンドを投入し「JupyterLab」というコーディング環境をインストールする。
pip install jupyterlab[参考] pipコマンドが通らない場合
pipとは外部(https://pypi.org)からライブラリをダウンロードするコマンド。必然的にWebアクセスするため、会社のセキュリティポリシー上ではProxy設定等でエラーになるケースがある。その場合は以下に置き換えることでコマンドを通すことが可能。
pip install –proxy=http://<username>:<password>@<proxyのドメイン名 or IPアドレス>:<Port> <パッケージ名>
これ以外にもWheelファイルを直接ローカル環境にもってきてインストールする手段もある。
jupyterlabのライブラリが無事入ったら、以下のコマンドを実行。ブラウザが起動して以下の画面が表示されたら成功。NotebookのPython3(ipykernel)をクリックして新規ファイルを作成すれば、コーディング環境の準備は完了。
jupyter lab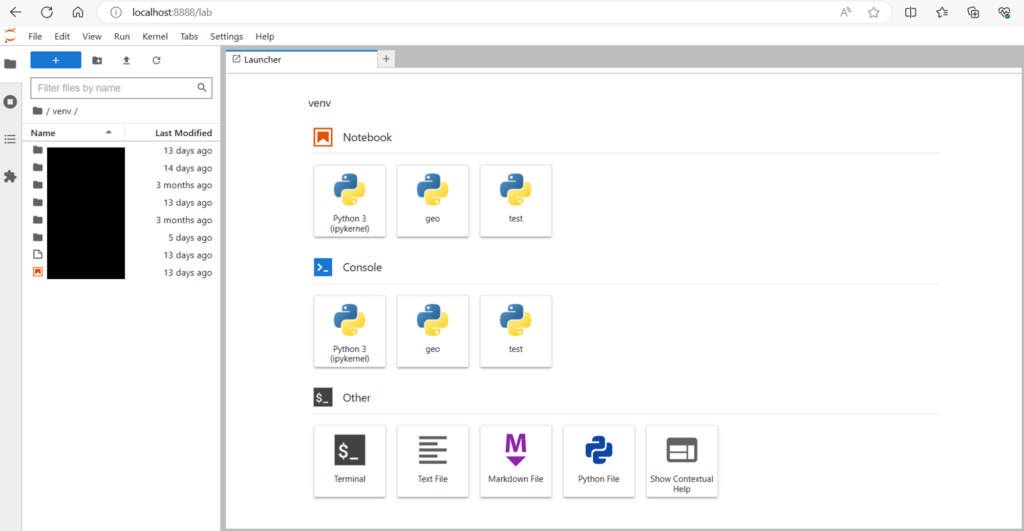
[参考] (初心者向け)Jupyter Labを使ったPythonの実行
基本は「コードを入力」→「ctrl+Enter(実行)」→「出力結果が表示される」→「+ボタンで次のコードを追加する」を繰り返す。以下に実際の手順例を示す。
コード入力:print("こんにちは")というコードを入力
実行:コード左側の再生ボタンを押下
出力結果:下部に「こんにちは」が出力
コード追加:左上の「+コード」を押下
以降の解説ではコード中心の説明なるが、基本的には当記事のコードブロック(背景:黒)からコードをコピペして実行。出力結果がでるのを待って、次のコードブロック(背景:黒)を実行...を繰り返すことで、コードの詳細が理解できていなくても実行は可能。

③PythonでRAGを実施する 難易度:★★★☆☆
詳しくは以下で解説。見るのが面倒な方は、必要なコマンドだけ軽く説明。
【No.L016】社内ドキュメント学習: RAG(Retrieval-Augmented Generation)技術の実装手順と実行方法 – GIS Academy
まずは必要なライブラリを準備するところからスタート。以下のコードをJupyter Labに貼り付けて実行。ネット環境に依存するが、特に問題なければ数分程度でインストールが完了する。
!pip install openai
!pip install chromadb
!pip install langchain
!pip install pypdf
!pip install tiktoken[参考] ライブラリのVersion
「pip install ライブラリ名」で検索をかけると最新版のライブラリがインストールされるが、場合によってはバージョンの互換性が合わずエラーが出る可能性がある。その場合は「pip install ライブラリ名==下記バージョン」で再インストールをおこなうことでエラー回避することが可能となる。
openai 1.25.0
chromadb 0.5.0
langchain 0.1.17
pypdf 4.2.0
tiktoken 0.6.0
続いて生成AI(モデル)とVectorDBの作成を実施を行う。先ほど取得したOpenAIのAPI KEYをプログラム内に記載すること。
import os
import platform
import openai
import chromadb
import langchain
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationalRetrievalChain
from langchain.document_loaders import PyPDFLoader
#任意のpdfファイルを指定
loader = PyPDFLoader("xxxxxx.pdf")
pages = loader.load_and_split()
#ご自身のOpenAIのAPIkeyを指定
os.environ["OPENAI_API_KEY"] = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
openai.api_key = os.getenv("OPENAI_API_KEY")
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(pages, embedding=embeddings, persist_directory=".")
vectorstore.persist()
pdf_qa = ConversationalRetrievalChain.from_llm(llm, vectorstore.as_retriever(), return_source_documents=True)[参考] コードをざっくり解説 embeddingsは文字をベクトル化するためのものであり、これを使ってVectorDB(社内資料の情報ベクトルを保持)を作成する。最後の行のコードでVectorDBと生成AIを連結させている。
query = "ここに好きな質問を記載する"
chat_history = []
result = pdf_qa({"question": query, "chat_history": chat_history})
#result["answer"]今回の記事はこれで終わり。


コメント