
はじめに
ReazonSpeechとは、株式会社レアゾン・ホールディングスが提供する高精度日本語音声認識モデルのこと。簡単に言うと音声ファイルからテキストを抽出するモデルのこと。具体的な活用事例として会議で録音した音声を文字起こしして議事録を作ること等が可能になる。参考にしたのはこちらのサイト。クイックスタート – Reazon Human Interaction Lab
★関連リンク
業務で活用できるAI技集のまとめはこちら
画像ファイルからテキストを抽出したい場合はこちら
少量の音声ファイルから好きな音声を喋らせたい場合はこちら
手順
⓪Google Colaboratoryにアクセスする [5分]
Google Colabを使うためにはGoogleのアカウント(無料)が必要。Googleアカウントをもっていない方は以下のサイトにアクセスし登録をおこなう(右上の「アカウントを作成する」から指示に従って対応)。既に持っている方は作業不要。
Google アカウント

アカウント作成のプロセスは「名前」→「生年月日」→「アカウント名」→「パスワード」→「再設定用メルアド(スキップ可能)」→「最終確認」の順で進んでいく。最後に「プライバシーと利用規約」に同意すれば晴れてアカウントが完了する。
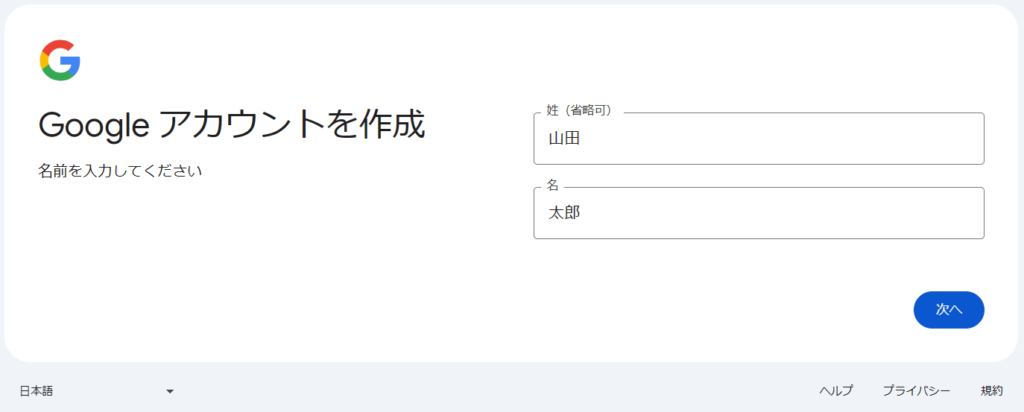
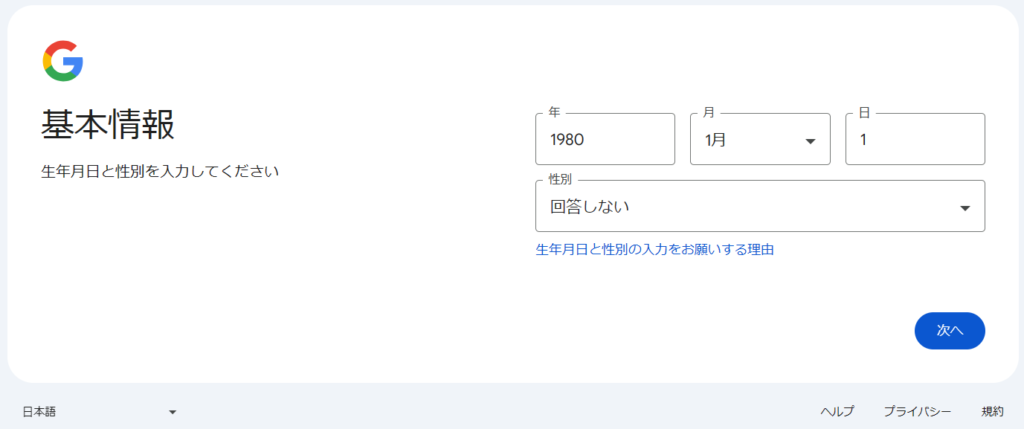
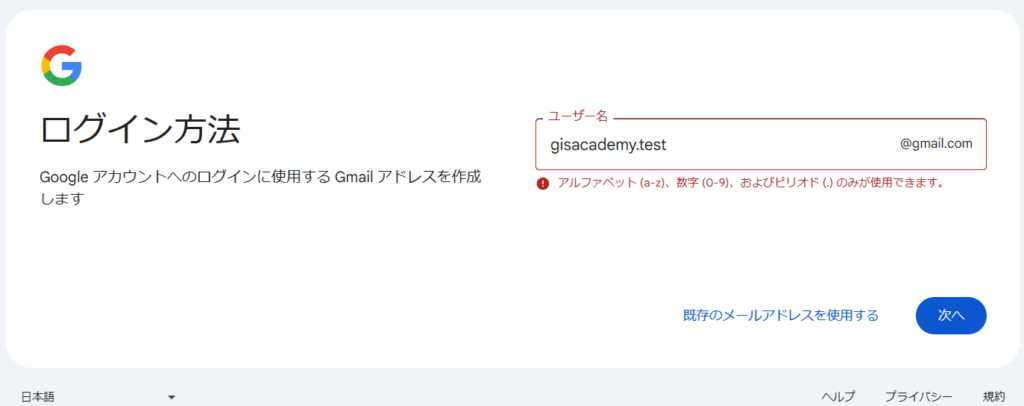
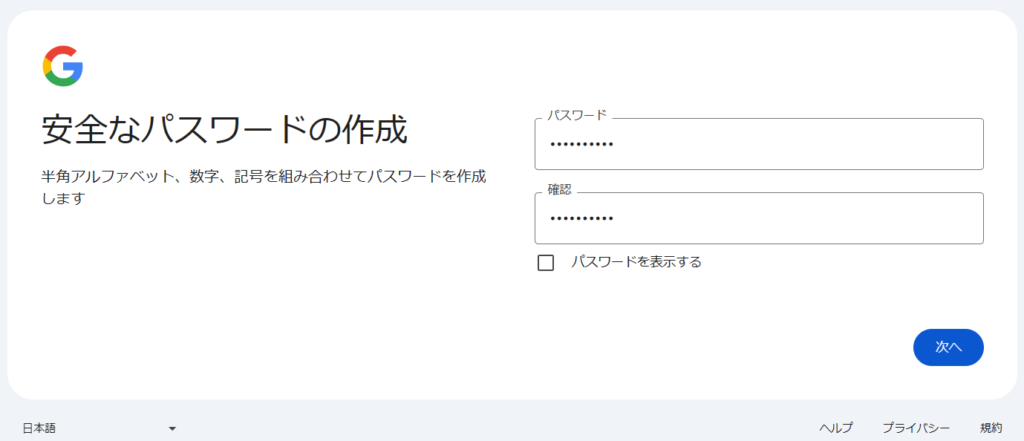
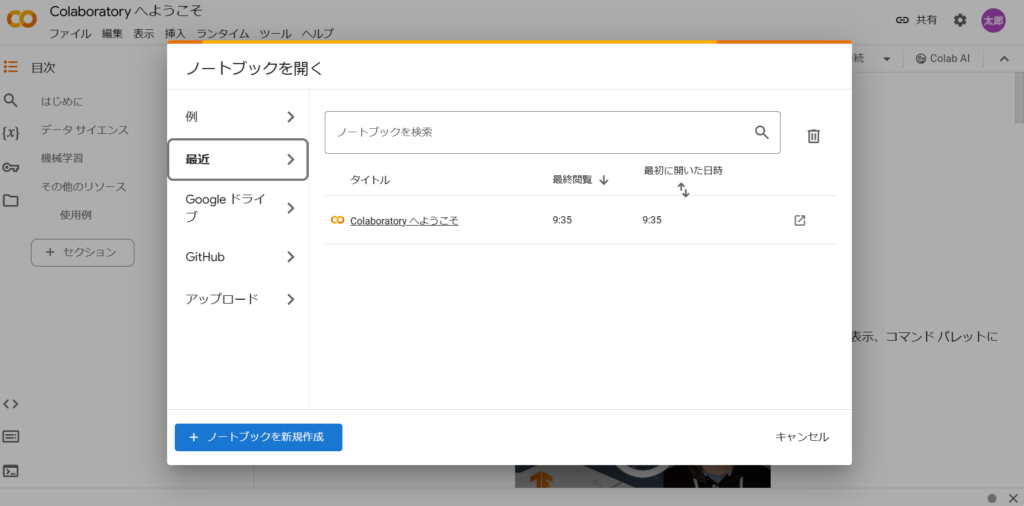
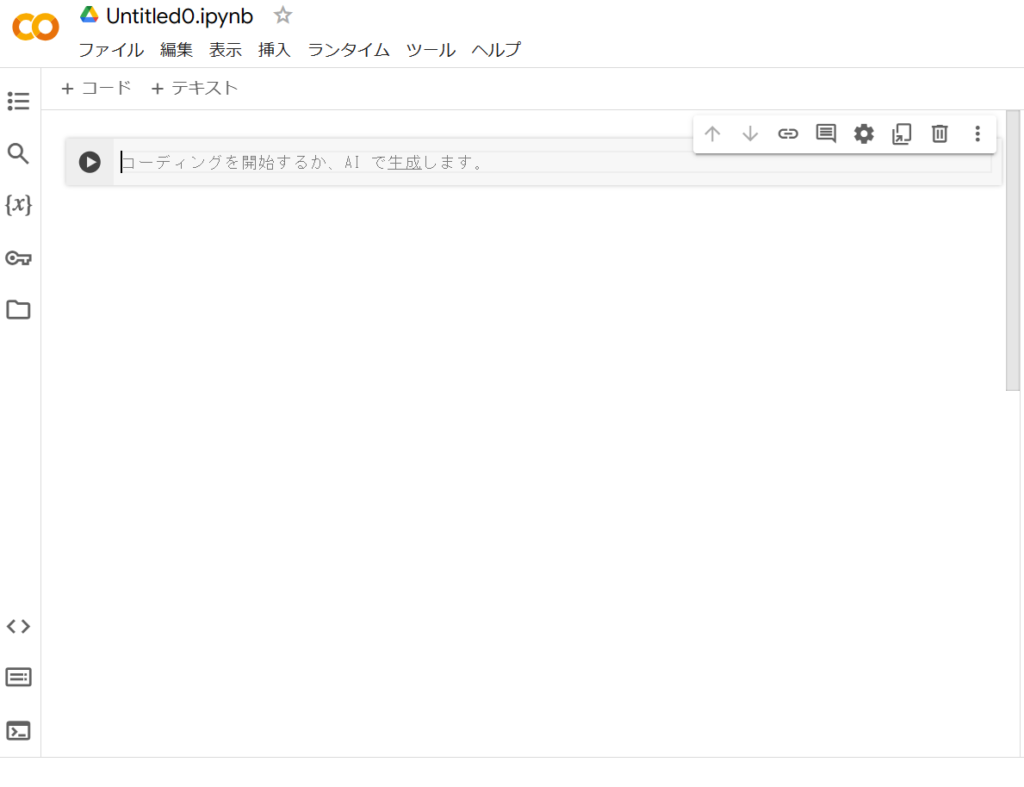
次にGoogle Colabにアクセスすると下左図のような画面が出てくるので「ノートブックを新規作成」を押す。するとPythonのコードを実行できる環境整備が完了する(下右図)。
[参考] (初心者向け)Google Colabを使ったPythonの実行
基本は「コード入力」→「再生ボタンを押す(実行)」→「出力結果が表示される」→「次のコードを追加する」を繰り返す。以下に実際の手順例を示す。
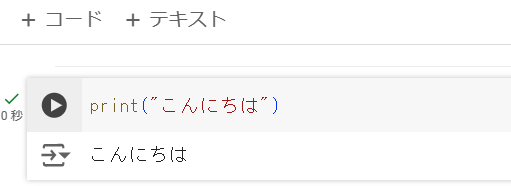
コード入力:print("こんにちは")というコードを入力
実行:コード左側の再生ボタンを押下
出力結果:下部に「こんにちは」が出力
コード追加:左上の「+コード」を押下
以降の解説ではコード中心の説明なるが、基本的には当記事のコードブロック(背景:黒)からコードをコピペして実行。出力結果がでるのを待って、次のコードブロック(背景:黒)を実行...を繰り返すことで、コードの詳細が理解できていなくても実行は可能。
①必要なライブラリ等のインストール [5分]
GoogleColabに以下のコマンドを投入を実行。ffmpegは動画や音声を扱うための多機能なツールやライブラリ。CythonはPythonとC言語を組み合わせて高速な拡張モジュールを作成するためのツール。
# ffmpegとCythonのインストール
!sudo apt install ffmpeg
!pip install Cython続いて本体のダウンロード&インストール。「pip’s dependency resolver does not currently…」というエラーが出て止まってしまったが、セッションを再起動し再度最初から実行したら成功。
# パッケージのインストール
!git clone https://github.com/reazon-research/ReazonSpeech
!pip install ReazonSpeech/pkg/nemo-asr[参考] セッションの再起動の警告について
原因は不明だが以下のポップが出てきても、セッションを再起動を押して最初から実行し直せば2度目は問題なく実行可能。

つづいてGoogleドライブをマウントする。GoogleドライブとはGoogle上で使えるファイルサーバーのことで、15GBまで無料で使うことができる(24.5.12時点)。マウントとは簡単にいうとGoogle colabからGoogleドライブへアクセスできるようにすること。
from google.colab import drive
drive.mount('/content/drive')②文字起こしの実行 [1分~]
テキスト化したい音声ファイル(wav,m4a,mp3)を任意の場所に置き、以下コマンドを実行。上手くいけばテキストが出力される。以下の例ではReasonSpeech配下にSampleフォルダを作成し、audio-0.wavというファイルを格納。とりあえず試すだけであれば、公式HPのspeech-001.wavを活用。
「気象庁は雪や路面の凍結による交通への影響、暴風雪や高波に警戒するとともに雪崩や屋根からの落雪にも十分注意するよう呼びかけています。」
という文章に近しい結果が出力されれば成功。
# 音声認識
!reazonspeech-nemo-asr "ReazonSpeech/Sample/speech-001.wav"[参考] Google Colab上でのファイル格納の方法
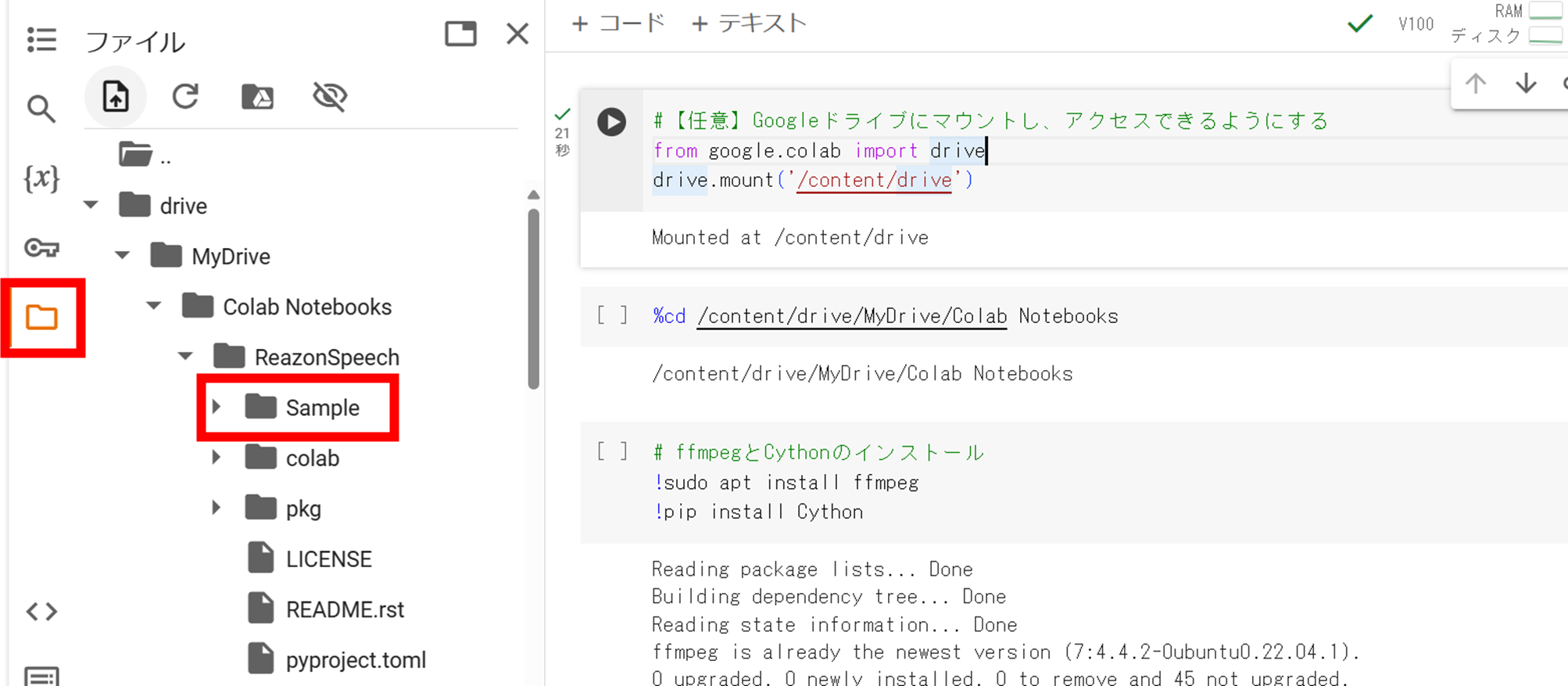
Googleドライブにマウントした状態(下図の右上コマンドを実行した状態)で左側にあるファイルアイコンをクリックすると、フォルダの階層がツリー表示される。主な操作は以下の通り。
・任意のフォルダ作成: 余白の部分で[右クリック]→[新しいフォルダ]
・ファイルのアップロード:ツリー表示上の格納先フォルダへファイルをドラッグ&ドロップ
※下図の赤枠(Sampleフォルダ)にファイルを重ねる
Appendix
かかった時間はモデルのダウンロードを除いて、20分位のサイズの音声ファイルで5分程度。ちなみに30分以上のファイルだとOOM(メモリー超過)して上手くいかなかったので、その場合は専用ツール等で分割すると良い(Free HD Video Converter Factoryー完全無料の高速、高品質動画変換ソフト)。ちなみに今回のGPUはGoogle ColabのGPU:V100で実行。
音声分割の方法は手順は以下の通り。
⓪音声ファイルを準備する
例えばiphoneを持っている方は録音機能(ボイスメモ)があるのでそれを活用。その後、録音した音声ファイル(m4a)をPCへ共有して保存する。(手段としては、AirdropやLINE、メール、MicrosoftアカウントがあればOnedrive等を活用)
①HD Video Converter Factoryを起動 [~1分]
②はさみマークを押下 [~1分]

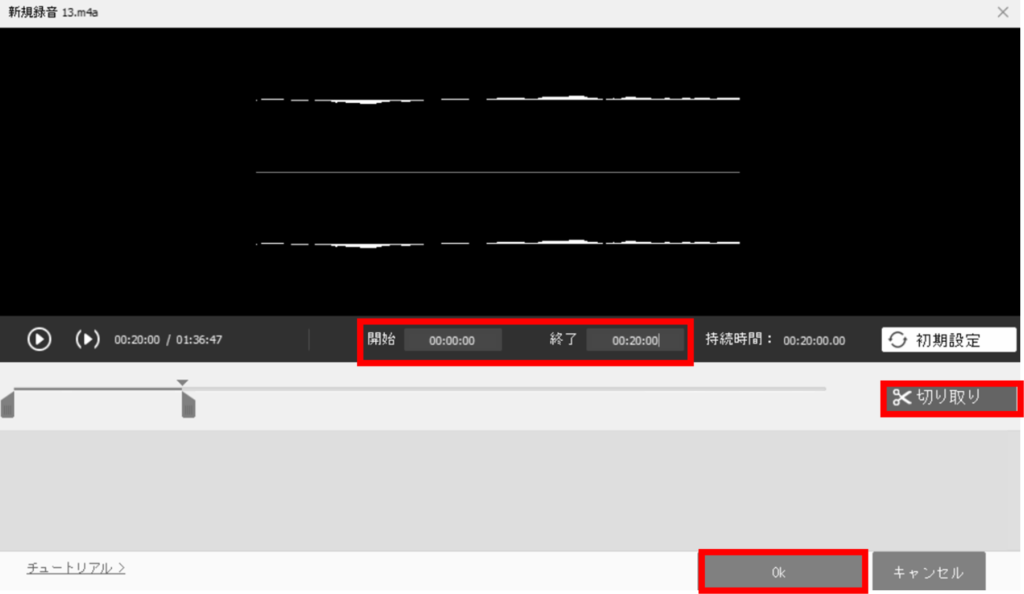
③任意のサイズに切り取り [~1分]
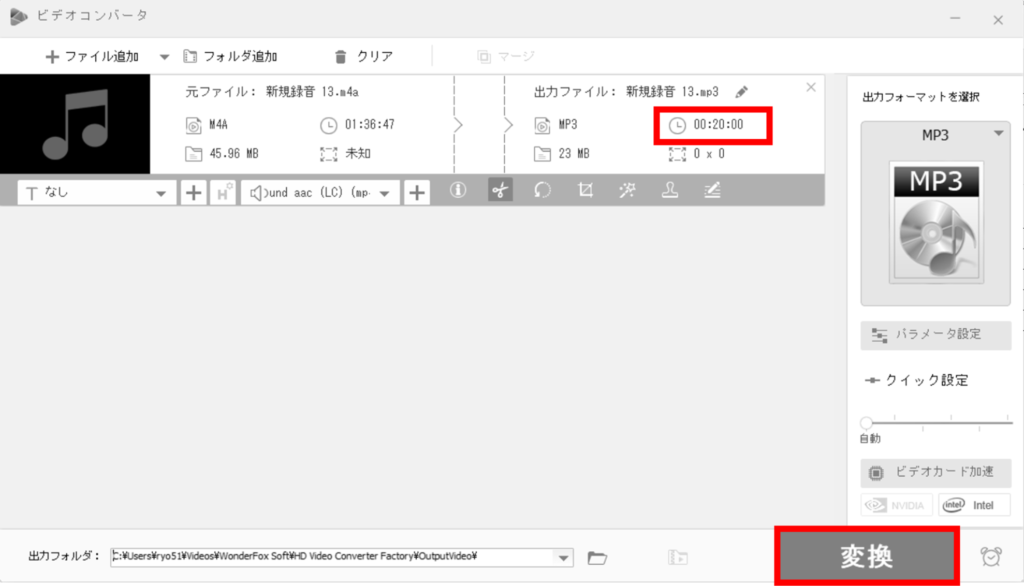
開始ー終了の時間を設定。経験上、GPUがV100程度であれば20分程度のサイズはOOM(メモリ超過)にならない。時刻を指定して、切り取りを行いOKをクリックする。
④変換 [~5分]
時間のサイズが指定したものになっているか確認。問題なければ変換ボタンを押下(出力の形式はMP3のままで問題なし)。出力フォルダにデータが保存される。
当記事に記載のあるコードを纏めたipynbファイルも併せて展開。


コメント