
はじめに
Stable Diffusionとは、簡単に言うと画像の生成AIで好きな単語から画像を作ったりできるモデルのこと。今回はそれをGoogle Colab上で動作させることを実践してみる。なおGoogle Colabの詳細についてはここでは詳しく触れず、Googleアカウントでログイン可能の前提で説明する。
★関連リンク
業務で活用できるAI技集のまとめはこちら
手順
①本体のダウンロード
GoogleColabにアクセスし、以下のコマンドを投入すると、同じディレクトリに「stable-diffusion-webui」のフォルダが作成される。
!git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui②Pythonファイルの実行
GPU環境じゃないと動かないので、[編集]→[ノートブックの設定]からGPUを選択。cdコマンドで移動してからpythonファイルを実行。数分すると、URLが発行されるので、コピーしてブラウザからアクセス。
!python stable-diffusion-webui/launch.py --share --enable-insecure-extension-access【参考】GPUが利用不可のエラーメッセージ
以下のメッセージが発生した場合、正しくGPUを設定できていない。

【参考】プログラム実行時に出力されるURL
実行に成功すると以下のようなメッセージが下部のほうに出現。このURLをブラウザで実行する。

最終的に以下のような画面が出てくれば成功。左上のプルダウンでモデルを選択。上部のテキストボックスにプロンプトを入力して右のボタンを押下することでお好みの画像が生成可能。
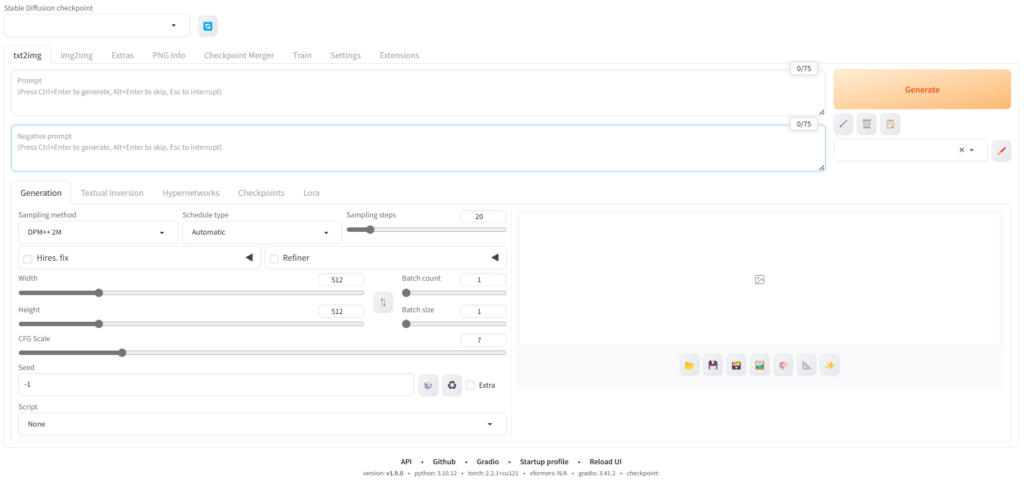
※違うモデルを使いたい場合
Defaultのモデル(v1-5-pruned-emaonly.safetensors)は汎用性が高い分、画像のクオリティがそこまで高くない。例えば人間の絵を表示したい場合、Defaultのままだと少し乱れた画像になってしまうことが多い。その場合は、モデルを追加する必要がある。
ただモデルは通常、数GB~の場合が多く、一度Webからローカル環境にDLしてそこからGoogleのクラウドにULするのは時間が掛かるため、Colab上で直接DLすることが望ましい。そのためのコマンドは以下である(下記例はBeautiful-Realistic-Asians-v7というモデルをDLする場合のコード)。URL(https://~~)は自分が欲しいモデルのDLリンクをコピーして貼り付け、-O以降のパスは保存先を指定する。通常、Stable Diffusionはmodelフォルダを読み込みに行くので、この場所にモデルを保存する形が望ましい。
#!wget https://civitai.com/api/download/models/177164 -O stable-diffusion-webui/models/Stable-diffusion/anylora.safetensorsかかった時間は15分程度。GPUさえあれば、恐らくローカル環境でも動作可能と思われる。
Appendix
モデルは主に以下の2つのサイトからダウンロード可能。
・Civitai
・Hugging Face
Civitaiについては、ダウンロード用のコマンドをColab上で実行し、直接モデルのファイルを保存するのが効率的。なおモデルの保存先は「stable-diffusion-webui/models/Stable-diffusion」の配下とすること。
| モデル名 | ダウンロード用のコマンド | 例 |
| anything v5 | !wget https://civitai.com/api/download/models/30163 -O stable-diffusion-webui/models/Stable-diffusion/anything_v5.safetensors |  |
| anylora | !wget https://civitai.com/api/download/models/177164 -O stable-diffusion-webui/models/Stable-diffusion/anylora.safetensors |  |
| chilled_remix | !wget https://huggingface.co/sazyou-roukaku/chilled_remix/resolve/main/chilled_remix_v2.safetensors -O stable-diffusion-webui/models/Stable-diffusion/chilled_remix.safetensors |  |
| Beautiful Realistic Asians | !wget https://civitai.com/api/download/models/177164 -O stable-diffusion-webui/models/Stable-diffusion/Beautiful-Realistic-Asians.safetensors |  |
| A-Regular-Deep-Background | !wget https://civitai.com/api/download/models/122339 -O stable-diffusion-webui/models/Stable-diffusion/A-Regular-Deep-Background.safetensors |  |
ちなみに4つの女性の画像は下記プロンプトで生成。
Prompt:
actual 8K portrait photo of gareth person, portrait, happy colors, bright eyes, clear eyes, warm smile, smooth soft skin, big dreamy eyes, beautiful intricate colored hair, symmetrical, anime wide eyes, soft lighting, detailed face, by makoto shinkai, stanley artgerm lau, wlop, rossdraws, concept art, digital painting, looking into camera
Negative Prompt:
painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime
なお、Hugging Faceについては、試しにジブリ調になるモデルを紹介。本記事ではHugging Faceのpipelineという機能を使うので、上記のStable DiffusionをDLしなくても動作は可能。所要時間は全行程で3分程度(GPU:V100)。
①必要ライブラリのインストール
!pip install diffusers==0.27.2②モデルの設定
from diffusers import StableDiffusionPipeline
import torch
model_id = "nitrosocke/Ghibli-Diffusion"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")③プロンプトの実行
prompt = "ghibli style girl"
image=pipe(prompt).images[0]
imageこんな感じの画像が出てくれば成功。
※プロンプトには必ず”ghibli style”の文字をいれること。

当記事に記載のあるコードを纏めたipynbファイルも併せて展開。


コメント